# ある動物の種類についての体重と分類群を調べました
# 複数の値を並べるときは カンマ , を使います
c(6, 3.5, 5.4)[1] 6.0 3.5 5.4# 文字列は 引用符 " で囲みます
c("食肉類", "鳥類", "食肉類")[1] "食肉類" "鳥類" "食肉類"データ分析を行う上では「データ」のことを知らなくては進めません。 データの種類は数値だけではありません。さらに数値にもいくつかのタイプがあります。 最近ではビックデータや機械学習の普及によりログデータや画像、動画ファイルをデータとして扱う機会も増えていますが、ここではデータの種類として古くから存在する表形式のデータを例に解説します。
データと言われて思い浮かべるものはなんでしょうか。 ここではデータをさまざまな計測や観察により得られる情報のことを示します。 対象から情報を引き出したものと言い換えることもできます。 多くは数値の形をしていますが、文字列である場合もあります。 データの例をあげてみましょう。 ある動物について、体の一部の大きさや体重を測る、雌雄を調べる。 これらはデータの一つです。 体の部位や体重は数値によって観測されますが、雌雄は「雄」や「雌」という文字列で記録されるのが一般的です。
Rを使ったデータの記述方法を紹介します。 ここではある動物の種類についての体重と分類群を調べた結果を入力します。 c()関数1の括弧の中(引数)に値である数値や文字列を記述します。 値と値の間にカンマ , を入力すると複数の値を記述することになります。 数値は直接入力できますが、文字列を与えるときは引用符 " で文字列を囲む必要があります。
# ある動物の種類についての体重と分類群を調べました
# 複数の値を並べるときは カンマ , を使います
c(6, 3.5, 5.4)[1] 6.0 3.5 5.4# 文字列は 引用符 " で囲みます
c("食肉類", "鳥類", "食肉類")[1] "食肉類" "鳥類" "食肉類"「複数の動物の体重」のように、共通の手法によって得られた値のことを変数といいます。 動物の体重は、個体や種類が違うと値も変わります。 このように対象によって数値が変わるもの、変化する値を意味します。
体重を記録するときは数値を用いました。 このように数量を表す変数のことを量的変数といいます。 数値からなる変数なので、平均を求めたり大きい順番に並び替えるといった処理が可能です。
量的変数の場合、数値の種類によってさらに離散変数と連続変数に分類できます。 とり得る値が一定の間隔によりバラバラな変数を離散変数と呼びます。 例えばサイコロの出目は一般的に1から6までの整数であるため、離散変数です。 また動物を1頭、2頭と数えた個体数も同じです。
離散型の量的変数に対し、連続値で表現される変数を連続変数といいます。 3.5\(kg\)、5.4\(kg\)のように表現される体重は連続変数です。
では雌雄や分類群はどのように記録するのが適切でしょうか。 これらは数量として扱いにくいものです。 「雄」や「雌」、「鳥類」や「霊長類」という具合に項目を変数として扱う場合、 それは質的変数またはカテゴリ変数と呼ばれます。 質的変数は量的変数のように足し算や引き算といった計算ができないのが特徴です。
変数の性質により、量的変数と質的変数をより細かく分類することもあるよ。 尺度水準と呼ばれる基準を用いると、量的変数は間隔尺度と比例尺度に、質的変数は名義尺度と順序尺度に分けて考えることができるんだ。それぞれの特徴を説明するね。
例) 華氏で記録した温度例) 動物の保全状況例) 雌雄、動物の分類群データの種類に応じて名前がついている理由は、 データの種類によって適切なデータ分析の手法が異なるためです。 データ分析を行う際は、データがどの種類の変数なのか意識することが大切です。
データ分析の作業においては、データの変数を比較し、関係を調べることが頻繁に行われます。 特定の個体や観測について複数の項目を同時に扱えるようにするために、データを表形式でまとめて表現します。 これを表データまたはデータフレームと呼びます。
データフレームの例として、いくつかの動物の体の大きさ(体長)と体重の記録をデータフレームにまとめてみましょう。 データフレームでは個人や個体、観測といったデータを一つの行にまとめます。 レッサーパンダの体長と体重の行、チンパンジーの体長と体重の行と、それぞれの値を行単位で記録します。 22種類の動物のデータをとった場合は22行、40種の動物についてであれば40行となりますね。 また、動物の分類群や名前や体長、体重といった変数を列として表します。
df_zoo_subset| 分類群 | 動物の名前 | 体長(cm) | 体重(kg) |
|---|---|---|---|
| 食肉類 | レッサーパンダ | 63.5 | 6 |
| 霊長類 | チンパンジー | 85.0 | 60 |
| 霊長類 | マントヒヒ | 80.0 | 20 |
| 食肉類 | ライオン | 250.0 | 225 |
| 鳥類 | フンボルトペンギン | 69.0 | 6 |
データフレームではデータを横に見たものが行、縦に見たものを列と考えます。 表 2.1 のデータフレームは5行4列のデータフレームといえます。
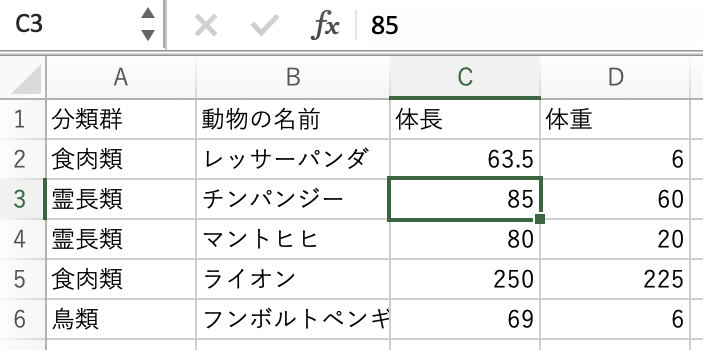
表計算ソフトウェアにデータを記録するときもデータフレームと同じ形式をとるよ。 ここでは1,2,3といった数字が行、A、B、Cといったアルファベットが列を示しているね。 それぞれの値を記録している場所のことをセルというよ。 これはデータを記録している番地のようなもので、例えば、チンパンジーの体重はC3を参照すれば良いことになるね。
先ほど5種の動物のデータフレームを示しましたが、データ分析を進めていくには より多くのデータが必要になります。 たくさんのデータがあれば、データから見えてくる傾向・パターンも見えやすくなります。 ここでは22種の動物について、同様の体長、体重を調べたデータを用意しました。 ここからはこの動物データ (表 2.2) を使い、データを調べていくことにします。 このデータはとくしま動物園で 飼育される動物について記録したものです。詳細は付録データセットで解説しています。
動物データはcsvファイルと呼ばれるテキストファイルの一種に記録されたデータです。 csvファイルはデータを記録するためのファイル形式として広く使われるもので、 カンマ , によって変数を区切っていくのが特徴です。 データフレーム同様、個体や観測のデータを一つの行にまとめます。 具体的には動物データの中身は次のようになっています。
taxon,name,body_length_cm,weight_kg
食肉類,レッサーパンダ,63.5,6
鳥類,ホオジロカンムリヅル,100,3.5
食肉類,コツメカワウソ,64,5.4
以下省略...Rではcsvをはじめとした各種ファイルをデータフレームとして扱うための関数が用意されています。 read.csv()関数でcsvファイルを読み込むには、関数の第一引数にファイルのパス(置き場所)を文字列で与えて実行します。データはdf_zooというオブジェクトに格納され、いつでも表示(参照)できるようになっています。
# dfはデータフレーム(data frame)の頭文字から
# 動物データの読み込み
df_zoo <-
read.csv("data-raw/tokushima_zoo_animals22.csv")df_zoo| taxon | name | body_length_cm | weight_kg |
|---|---|---|---|
| 食肉類 | レッサーパンダ | 63.5 | 6.0 |
| 鳥類 | ホオジロカンムリヅル | 100.0 | 3.5 |
| 食肉類 | コツメカワウソ | 64.0 | 5.4 |
| 鳥類 | カナダガン | 110.0 | 6.5 |
| 霊長類 | チンパンジー | 85.0 | 60.0 |
| 霊長類 | シシオザル | 66.0 | 10.0 |
| 霊長類 | マントヒヒ | 80.0 | 20.0 |
| 食肉類 | ピューマ | 168.0 | 80.0 |
| 齧歯類 | カピバラ | 134.0 | 66.0 |
| 食肉類 | ライオン | 250.0 | 225.0 |
| 鳥類 | アフリカハゲコウ | 130.0 | 9.0 |
| 偶蹄類 | シロオリックス | 175.0 | 220.0 |
| 食肉類 | ミーアキャット | 31.0 | 0.9 |
| 食肉類 | シンリンオオカミ | NA | 30.3 |
| 鳥類 | アンデスコンドル | 1.2 | 15.0 |
| 食肉類 | ホッキョクグマ | 250.0 | 410.0 |
| 霊長類 | リスザル | 35.0 | 1.1 |
| 鳥類 | フンボルトペンギン | 69.0 | 6.0 |
| 鯨偶蹄類 | ラマ | NA | 140.0 |
| 奇蹄類 | ポニー | NA | NA |
| 齧歯類 | モルモット | 40.0 | 1.5 |
| 鯨偶蹄類 | ヒツジ | NA | NA |
上記のコマンドの実行により、データフレームが出力されたかと思います。 一行目の出力が変数を示しています。これは列の名前(列名)とも呼ばれます。 データフレームをプログラミング言語で扱うときはこの列名にはできるだけ英語やローマ字を使ったものにしましょう。 漢字やひらがなを使うと意味がわかりやすいですが、海外で開発されたRのようなプログラムは日本語の扱いに不自由な点があるためです。 ここでも次のように動物データの列名を日本語から英語に変えてあります。
taxon: 動物の分類群name: 動物の種名body_length_cm: 体長(単位はcm)weight_kg: 体重(単位はkg)変数を参照するにはドル記号 $を使います。
# データフレーム中の変数を参照するにはドル記号 $ に続けて変数名を与えます。
df_zoo$name [1] "レッサーパンダ" "ホオジロカンムリヅル" "コツメカワウソ"
[4] "カナダガン" "チンパンジー" "シシオザル"
[7] "マントヒヒ" "ピューマ" "カピバラ"
[10] "ライオン" "アフリカハゲコウ" "シロオリックス"
[13] "ミーアキャット" "シンリンオオカミ" "アンデスコンドル"
[16] "ホッキョクグマ" "リスザル" "フンボルトペンギン"
[19] "ラマ" "ポニー" "モルモット"
[22] "ヒツジ" ファイルを用意せずに、直接データフレームの生成もできます。 これにはdata.frame()関数とc()関数を使います。 data.frame()関数の引数に変数名 = 値の形式でデータを与えていきます。 文字列の変数は引用符 " で囲む点、データの区切りにはカンマ , を使う点に注意してください。
data.frame(
taxon = c("食肉類", "鳥類", "食肉類"),
name = c("レッサーパンダ", "ホオジロカンムリヅル", "コツメカワウソ"),
body_length_cm = c(6.0, 3.5, 5.4),
weight_kg = c(63.5, 100, 64.0))cは「組み合わせる」の英単語であるcombineに由来します。↩︎