x1 = 0
x2 = 0
(0.5 * x1 + 0.5 * x2 <= 0.7) & (0.5 * x1 + 0.5 * x2 > 0.7)False深層学習は人工ニューロンと呼ばれる、人の脳で行われている情報処理を模倣した情報処理モデルを多層に重ねたニューラルネットワークを用いて、データから重要な特徴量を抽出し、その特徴量を用いて分類や回帰を行う機械学習の手法です。
深層学習は、画像認識や音声認識、自然言語処理などの分野で高い精度を出しており、近年では様々な分野で活用されています。人工知能の中でも、特に注目されている技術です。
深層学習は機械学習の一種ですが、機械学習とはどのような違いがあるのでしょうか。機械学習と深層学習の特徴・その違いを整理すると、以下のようになります。
深層学習で利用される人工ニューロンは、人間の脳の神経細胞を模倣したものです。人間の脳は、神経細胞と呼ばれる細胞が結びつき、神経細胞同士で電気信号を伝えるネットワークを形成しており、このネットワークをニューラルネットワークと呼びます。
神経細胞のネットワークは、以下のような構造をしています。
軸索末端と次のニューロンの樹状突起とが接触し、情報の伝達が行われます。この接触部位はシナプスと呼ばれます。また、電気信号の伝達を「発火」と呼びます。
発火は、樹状突起からの入力が一定の値を超えたときに発生します。この一定の値を閾値と呼びます。閾値を超えたときに発生する電気信号の強さは一定であり、発火の有無のみが伝達されます。
人工ニューロンは、ニューラルネットワークを構成する基本単位としての、モデル化された神経細胞です。1つ以上の入力を受け取り、それらの入力に対して重み付けを行い、その重み付けの総和を活性化関数に入力した値を出力する、という構造をしています。
人工ニューロンの一種に「パーセプトロン」と呼ばれるものがあります。パーセプトロンの挙動を理解することで、人工ニューロンの基本的な動作の理解に役立ちます。
パーセプトロンは、構造や学習の違いによって、単純パーセプトロンと多層パーセプトロンに分けられます。まずは単純パーセプトロンについて説明します。
単純パーセプトロンは、入力層と出力層の2つの層から構成されています。入力層は、入力を受け取る層です。出力層では、入力層からの入力と重みの積の総和が閾値を超えた場合に1を出力し、超えなかった場合に0を出力する、という動作をします。このような動作を行う関数を「ステップ関数」と呼びます。パーセプトロンでは、ステップ関数のように、入力に対して出力を決定する関数を活性化関数と呼びます。
ステップ関数を活性化関数として用いた単純パーセプトロンは以下の式で表現されます。 \[ y = \begin{cases} 0 & (w_1x_1 + w_2x_2 \leq \theta) \\ 1 & (w_1x_1 + w_2x_2 > \theta) \end{cases} \]
ここで \(x1\) 、\(x2\) は入力、 \(w1\) 、\(w2\) は各入力に対する重み(weight)、 \(\theta\) は閾値です。ここでは入力の数が2つの場合を考えていますが、入力の数は任意の値にすることができます。また、入力の重要度を重みによって調整することができます。そのため重みは入力ごとに用意されています。 \(\theta\) は、重みと入力の積の総和が閾値を超えた場合に1を出力するかどうかを決定するための値です。すなわち、 \(\theta\) が大きいほど、重みと入力の積の総和が大きくないと1を出力しなくなります。
1か0かという二値の出力を用いて、以下の論理演算を行うことができます。このような論理演算を行うパーセプトロンを「論理回路」と呼びます。
| \(x_1\) | \(x_2\) | AND | OR | NAND |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
これらの論理演算は、パーセプトロンの重みと閾値を適切に設定することで実現できます。例えば、ANDの場合は、 \(w_1\) 、 \(w_2\) 、 \(\theta\) をそれぞれ0.5、0.5、0.7とすると、上の表のような出力が得られます。
\[ y = \begin{cases} 0 & (0.5x_1 + 0.5x_2 \leq 0.7) \\ 1 & (0.5x_1 + 0.5x_2 > 0.7) \end{cases} \]
x1 = 0
x2 = 0
(0.5 * x1 + 0.5 * x2 <= 0.7) & (0.5 * x1 + 0.5 * x2 > 0.7)FalsePythonで上記のパーセプトロンを実装すると以下のようになります。
def perceptron(x1, x2, theta = 0.7):
w1, w2 = 0.5, 0.5
tmp = w1 * x1 + w2 * x2
if tmp <= theta:
return 0
elif tmp > theta:
return 1
print(perceptron(0, 0)) # 0
print(perceptron(1, 0)) # 0
print(perceptron(0, 1)) # 0
print(perceptron(1, 1)) # 10
0
0
1Pythonで実装したパーセプトロンは、「入力と重みの積の総和が閾値を超えた場合に1を出力し、超えなかった場合に0を出力する」、という動作をしています。閾値は関数の引数として与えていましたが、この値を変えることで、パーセプトロンの出力を変えることができます。これにより、パーセプトロンをORパーセプトロンとして機能させることができます。
# ORのパーセプトロン
print(perceptron(0, 0, theta = 0.2)) # 0
print(perceptron(1, 0, theta = 0.2)) # 1
print(perceptron(0, 1, theta = 0.2)) # 1
print(perceptron(1, 1, theta = 0.2)) # 10
1
1
1NANDのパーセプトロンは、ANDのパーセプトロンの重みと閾値を反転させることで実現できます。
# NANDのパーセプトロン
def NAND_perceptron(x1, x2, theta = -0.7):
# 重みと閾値を反転
w1, w2 = -0.5, -0.5
tmp = w1 * x1 + w2 * x2
if tmp <= theta:
return 0
elif tmp > theta:
return 1
print(NAND_perceptron(0, 0)) # 1
print(NAND_perceptron(1, 0)) # 1
print(NAND_perceptron(0, 1)) # 1
print(NAND_perceptron(1, 1)) # 01
1
1
0これまでのパーセプトロンの例では、閾値を関数の引数として与えていましたが、閾値をバイアスとして扱い、重みと入力の積の総和に含めることができます。
\[ y = \begin{cases} 0 & (b + w_1x_1 + w_2x_2 \leq 0) \\ 1 & (b + w_1x_1 + w_2x_2 > 0) \end{cases} \]
ここで \(b\) はバイアスです。この場合、閾値はバイアスの重みとなります。バイアスは、入力が0の場合に出力する値を決めるパラメータとして機能します。すなわちバイアスが大きいほど、入力が0の場合に出力する値は大きくなります。
# バイアスを導入したANDのパーセプトロン
def AND_perceptron(x1, x2, b = -0.7):
w1, w2 = 0.5, 0.5
# b はバイアス
tmp = b + w1 * x1 + w2 * x2
if tmp <= 0:
return 0
elif tmp > 0:
return 1
print(AND_perceptron(0, 0)) # 0
print(AND_perceptron(1, 0)) # 0
print(AND_perceptron(0, 1)) # 0
print(AND_perceptron(1, 1)) # 1
print("バイアスの値を小さくする")
# バイアスの値が小さいと発火しやすくなる
print(AND_perceptron(0, 0, b = -0.2)) # 0
print(AND_perceptron(1, 0, b = -0.2)) # 1
print(AND_perceptron(0, 1, b = -0.2)) # 1
print(AND_perceptron(1, 1, b = -0.2)) # 1
# バイアスの値が大きいと発火しにくくなる
print("バイアスの値を大きくする")
print(AND_perceptron(0, 0, b = -20.0))
print(AND_perceptron(1, 1, b = -20.0))0
0
0
1
バイアスの値を小さくする
0
1
1
1
バイアスの値を大きくする
0
0同様に、ORやNANDのパーセプトロンにもバイアスを導入することができます。
パーセプトロンを用いることで、ANDやOR、NANDの論理回路を表現することができました。一方で、2つの入力が異なる場合に1を出力し、同じ場合に0を出力する論理回路であるXORは単純パーセプトロンでは表現できません。
| \(x_1\) | \(x_2\) | \(y\) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
単純パーセプトロンがXORを表現できない理由は、単純パーセプトロンは線形分離可能な問題しか表現できないからです。線形分離可能な問題とは、2つのクラスを直線で分離できる問題のことです。XORは、2つのクラスを直線で分離するものではないため、単純パーセプトロンでは表現できない、ということになります。
import numpy as np
import matplotlib.pyplot as plt
# XORの入出力と線形分離不可能なことを確認する
# XORの入力
X = np.array([[0, 0], [1, 0], [0, 1], [1, 1]])
# XORの出力
Y = np.array([0, 1, 1, 0])
# データをプロットする
plt.scatter(X[:, 0], X[:, 1], c = Y)
# 直線の追加... これでは分離できない
plt.plot([0, 1], [1, 0])
plt.show()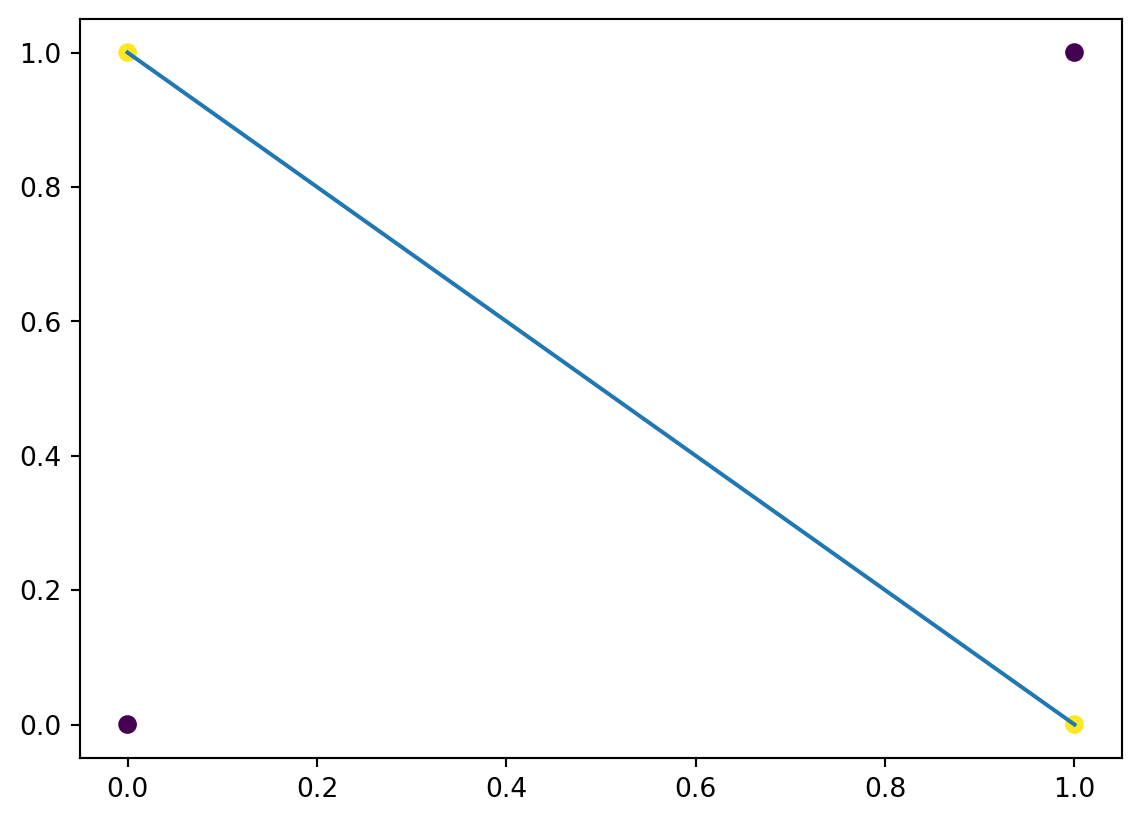
一方で、多層パーセプトロンを用いることで、XORを表現することができます。
多層パーセプトロンは、複数のパーセプトロンを組み合わせることで表現することができます。これにより、単純パーセプトロンでは表現できない非線形な問題を表現することができます。
バイアスを導入したANDパーセプトロンとORパーセプトロンを組み合わせることで、XORを表現することができます。これらの単純パーセプトロンを組み合わせて、XORを表現する多層パーセプトロンを作成してみましょう。
# ANDパーセプトロン
def AND_perceptron(x1, x2, b = -0.7):
w1, w2 = 0.5, 0.5
# b はバイアス
tmp = b + w1 * x1 + w2 * x2
if tmp <= 0:
return 0
elif tmp > 0:
return 1
# ORパーセプトロン
def OR_perceptron(x1, x2, b = -0.2):
w1, w2 = 0.5, 0.5
# b はバイアス
tmp = b + w1 * x1 + w2 * x2
if tmp <= 0:
return 0
elif tmp > 0:
return 1
# NANDパーセプトロン
def NAND_perceptron(x1, x2, b = 0.7):
w1, w2 = -0.5, -0.5
# b はバイアス
tmp = b + w1 * x1 + w2 * x2
if tmp <= 0:
return 0
elif tmp > 0:
return 1
# XORパーセプトロン
# XORはAND, OR, NANDを組み合わせて表現できる
def XOR_perceptron(x1, x2):
# 第0層(入力層)... 2つの入力を受け取る最初の層
s1 = NAND_perceptron(x1, x2)
# 第1層(中間層)... NANDパーセプトロンの出力を入力として受け取る
s2 = OR_perceptron(x1, x2)
# 第2層(出力層)... ORパーセプトロンとNANDパーセプトロンの出力を入力として受け取り、ANDパーセプトロンの出力を返す
y = AND_perceptron(s1, s2)
return y
# XORパーセプトロンの出力
for x1, x2 in X:
print(x1, x2, XOR_perceptron(x1, x2))0 0 0
1 0 1
0 1 1
1 1 0上記の多重パーセプトロンは3種の単純パーセプトロンを組み合わせて表現しています。このように、多層パーセプトロンは複数のパーセプトロンを組み合わせて表現することができます。これにより、多層パーセプトロンは非線形な問題を表現することができます。言い換えると、層を重ねることで、柔軟な表現が可能になったということです。
多層パーセプトロンをベースに、ニューラルネットワークの概念を紹介します。ニューラルネットワークは多層パーセプトロンと同じく、複数のパーセプトロンを組み合わせて表現することができます。しかし、ニューラルネットワークでは、パーセプトロンの重みとバイアスを自動で調整することができます。これらのパラメータを調整することを「学習」と呼んでいます。
ニューラルネットワークは、入力層、中間層、出力層の3つの層で構成されます。入力層は、外部からの入力を受け取る層です。中間層は、入力層からの入力を受け取り、出力層への入力を行う層です。出力層は、中間層からの入力を受け取り、外部への出力を行う層です。これは、多層パーセプトロンと同じ構造です。多層パーセプトロンと異なる点は、中間層が複数存在することです。このように、中間層が複数存在するニューラルネットワークは「層が深い」と表現され、ディープニューラルネットワークと呼ばれる所以になっています。
しかし、層の数を増やすだけでは、ニューラルネットワークの表現力は向上しません。ニューラルネットワークの表現力を向上させるには、活性化関数を工夫する必要があります。活性化関数には、ステップ関数以外にも、シグモイド関数やReLU関数などがあります。これらについて詳しく見ていきましょう。
「活性化」とは入力信号の総和がどのように発火するか(出力が1か0か)を決定することを指します。活性化関数はその名の通り、入力信号の総和がどのように活性化するかを決定する関数です。活性化関数には、ステップ関数、シグモイド関数、ReLU関数などがあります。
入力と出力の関係をグラフで表すと、以下のようになります。
# ステップ関数
def step_function(x):
return np.array(x > 0, dtype=np.int)
# シグモイド関数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# ReLU関数
def relu(x):
return np.maximum(0, x)
# 入力値
x = np.arange(-5.0, 5.0, 0.1)
# ステップ関数の出力
y_step = step_function(x)
# シグモイド関数の出力
y_sigmoid = sigmoid(x)
# ReLU関数の出力
y_relu = relu(x)
# グラフの描画
plt.plot(x, y_step, label='step')
plt.plot(x, y_sigmoid, label='sigmoid')
plt.plot(x, y_relu, label='ReLU')
plt.ylim(-0.1, 1.1)
plt.legend()
plt.show()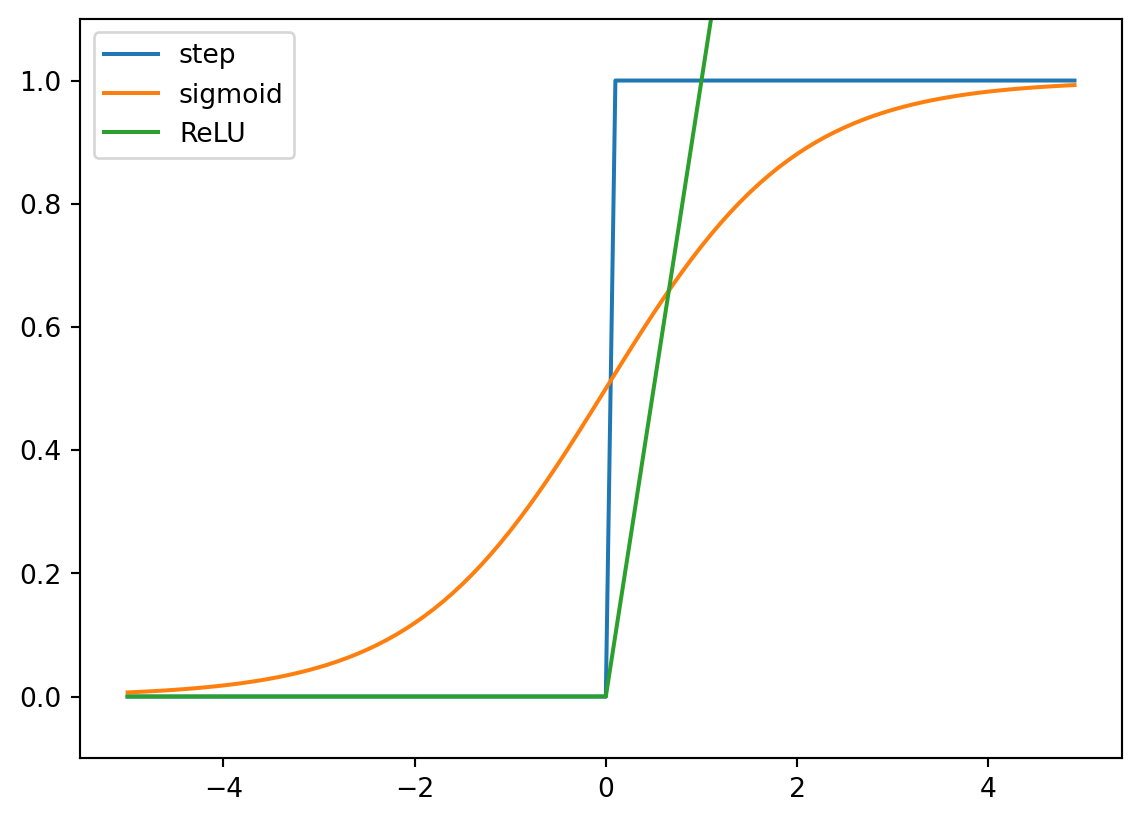
活性化関数の主な目的は、モデルに非線形性を導入し、より複雑な関数を近似する能力を提供することです。ニューラルネットワークでは、活性化関数として上記のシグモイド関数やReLU関数を用いることが多いです。ステップ関数は、ニューラルネットワークではあまり用いられません。
ニューラルネットワークにおいて、各中間層のニューロンは、その入力に対して重みを適用し、バイアスを追加した後、活性化関数を適用します。活性化関数は出力層でも使用されることがありますが、その選択は解くべき問題に依存します。たとえば、二項分類問題ではシグモイド関数が、多クラス分類問題ではソフトマックス関数が出力層の活性化関数としてよく使用されます。
ニューラルネットワークの実装は、多層パーセプトロンの実装とほぼ同じです。違いは、活性化関数をシグモイド関数やReLU関数に変更することです。また、中間層が複数存在することも違いの一つです。
# シグモイド関数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 恒等関数... 入力をそのまま出力する関数
def identity_function(x):
return x
# 3層ニューラルネットワーク
# 重みとバイアスを初期化する
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
# 入力信号を出力へ変換する処理
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
# 出力層の活性化関数は、恒等関数を用いる
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [0.31682708 0.69627909][0.31682708 0.69627909]扱う問題が回帰か分類かによって、出力層の活性化関数は変更します。回帰問題では、恒等関数を、分類問題では、ソフトマックス関数を用います。ソフトマックス関数は、出力層のニューロンの数だけの出力を持ち、その出力の総和が1になるように正規化します。そのため、ソフトマックス関数の出力を確率として解釈することができます。
ニューラルネットワークの学習では、ハイパーパラメータと呼ばれるパラメータが存在します。これは重みやバイアスのように、学習の過程で調整されるパラメータではなく、あらかじめ設定が必要なパラメータです。ハイパーパラメータには、エポック数、バッチサイズ、学習率などがあります。
ハイパーパラメータは以下に示すように、ニューラルネットワークの学習の進め方を決定する要因となります。そのため、ハイパーパラメータの値を適切に設定することは、ニューラルネットワークの学習を成功させるために重要です。
ニューラルネットワークの学習では、訓練データを複数回繰り返し用いて学習を行います。このとき、訓練データをすべて用いて1回学習を行うことを1エポックと呼びます。例えば1万件の訓練データに対してバッチサイズを100とした場合、すべての訓練データを用いて学習するには100回の繰り返しが必要です。このとき、100回の繰り返しが1エポックとなります。
モデルが訓練データに対して学習した回数をエポック数と呼びます。エポック数が大きいほど、モデルは訓練データに対してより多く学習することになります。エポックの数は、学習の反復回数を制御するためのハイパーパラメータとなります。そのためエポック数が小さいと、学習が十分に進まず、モデルの性能が低くなります。一方、エポック数が大きすぎると過学習しやすくなります。
ニューラルネットワークの学習、すなわちパラメータの更新は通常、訓練データ全体を一度に処理するのではなく、小さな「ミニバッチ」に分割して行われます。ミニバッチは訓練データセットからランダムに選ばれた一部のデータの集まりで、ミニバッチの大きさをバッチサイズと呼びます。このようなミニバッチを用いた学習を「ミニバッチ学習」と呼びます。
バッチサイズを大きく取る場合、1つのミニバッチを使った学習は、訓練データ全体を使った学習に近くなります。そのため、バッチサイズを大きく取ると、ミニバッチ学習の効率が良くなります。一方で学習時間が長くなり、メモリの使用量も増えます。
学習率とは、パラメータの更新量を決定するハイパーパラメータです。通常、0より大きく1以下の実数であり、その値は実験や経験に基づいて決定されます。
学習率が大きい場合は、大きくパラメータを更新することができます。学習率が大きい場合は、最適なパラメータを早く見つけることができますが、最適なパラメータの探索が不安定になり、最適なパラメータを見過ごしてしまう可能性があります。このことを「発散」と呼びます。一方、学習率が小さすぎると、パラメータの更新が非常にゆっくりとしか進まず、適切なパラメータを見つけるのに必要な計算時間が非常に長くなるか、または最適な解に全く到達しない可能性があります。
イテレーションとは、パラメータの更新を行う回数を表します。イテレーションは、エポック数、バッチサイズ、学習率から計算することができます。たとえば、エポック数が10、バッチサイズが100、学習率が0.01の場合、イテレーション数は10,000となります。
最適化問題は、ある関数の最小値または最大値を見つける問題です。この関数は通常「目的関数」または「損失関数」と呼ばれます。最適化問題では、目的関数の最小値または最大値を求めるために、パラメータを調整します。このパラメータの調整を「最適化」と呼びます。また具体的な最適化の手法を「最適化アルゴリズム」と呼びます。
たとえば、線形回帰モデルでは、最適化アルゴリズムとして最小二乗法を用いて、モデルのパラメータ(傾きと切片)を調整します。最小二乗法は損失関数として平均二乗誤差を用います。これはモデルの予測値と真の値との間の誤差を表します。この損失関数を最小化するようにモデルのパラメータを調整することで、モデルの予測値と真の値との誤差を小さくすることができます。
最小二乗法は線形回帰問題の解法として広く知られていますが、線形代数の手法を用いた一度の計算が必要となり、パラメータの数が増えると計算量が膨大になり現実的でなくなる可能性があります。そのためニューラルネットワークでは一般的に、勾配降下法という最適化アルゴリズムを用いて、パラメータを調整します。
勾配とは、ある地点における関数の傾きのことです。勾配が正の場合は、関数の値が増加していることを意味し、勾配が負の場合は、関数の値が減少していることを意味します。勾配が0の場合は、関数の値が極値に達していることを意味します。つまり、勾配が0となるように、勾配を小さくする方向にパラメータを調整することで、損失関数の値を小さくすることができます。これを繰り返すことで、損失関数の値を小さくすることができます。このような手法を勾配降下法と呼びます。この方法は損失関数の勾配(つまり、パラメータを微小量変化させたときの損失関数の変化量)を計算し、その勾配が示す方向にパラメータを少しずつ更新していくものです。
勾配降下法では全ての訓練データを用いて、勾配を求めます。そのため、学習の順番(訓練データの与えられ方)によっては、最適なパラメータを得ることができない場合があります。また、訓練データが膨大な場合は、全ての訓練データを用いて勾配を求めることは現実的ではありません。そのため、訓練データの中からランダムに選んだ一部のデータ(ミニバッチと呼ばれる)を用いて、勾配を求める方法があります。この方法を確率的勾配降下法と呼びます。
確率的勾配降下法では、一部のデータを用いて勾配計算を行うため、計算コストを削減することができます。また、ランダムに選ばれたデータを用いて勾配計算を行うため、最適なパラメータを得ることができない可能性があります。しかし、ランダムに選ばれたデータを用いて勾配計算を行うことで、局所的な最適解(局所解)に陥ることを防ぐことができます。また、確率的勾配降下法では複数のミニバッチを利用しますが、これらのミニバッチを並列して計算することで、計算コストを削減することができます。これにはGPUを用いることで、高速に並列計算を行うことが期待されます。
勾配降下法は山下り(あるいは山登り)に例えられます。山の斜面を下るとき、最も急な斜面を下る方向に進むと、最も早く山を下ることができます。現在地から最も急な斜面を下る方向に進むことができるだけ進み、再び最も急な斜面を下る方向に進みます。これを繰り返すことで、最も急な斜面を下る方向に進むことができます。確率的勾配降下法では、進む方向にランダム性があるため、最も急な斜面を下る方向に進むことができない可能性があります。そのため、ジグザグとした動きで山を下ることになります。
ニューラルネットワークでの重みパラメータに対する損失関数の勾配を効率的に求める方法を誤差逆伝播法(バックプロパゲーション)と呼びます。誤差逆伝播法により、パラメータ数が非常に多いモデルでも、各パラメータに対する損失関数の勾配を効率的に計算することが可能となります。
誤差逆伝播法は次のような手順で行われます。まず、現在の重みとバイアスを元に入力データから出力を行い、損失関数の勾配を求める過程を「順伝播」と表現します。誤差逆伝播法はその名の通り、出力層から入力層へ向かって逆向きに「誤差」を伝播します。つまり、出力層から入力層へ向かって、各層の重みとバイアスの勾配を偏微分を用いて求めることができます。ここで得られた勾配を用いて、重みとバイアスのパラメータを更新します。具体的には、パラメータをその勾配方向に小さなステップ移動させて、損失関数の値を少しずつ減らしていきます。
誤差逆伝播法では、出力層から入力層へ向かって誤差を伝播させます。そのため、誤差逆伝播法では、出力層に近い層の重みパラメータの勾配が正しく計算されることが期待されます。一方、出力層から遠い層の重みパラメータの勾配は、誤差逆伝播法では正しく計算されない可能性があります。具体的には勾配が非常に小さくなり、0になってしまうことがあります。そのため、重みパラメータが更新されず、学習が進まなくなることがあります。これを勾配消失問題と呼びます。
勾配消失問題は特に、活性化関数にシグモイド関数を用いる場合に発生します。シグモイド関数は、層を重ねるごとに勾配が小さくなり、0に近づいていきます。そのため、層を重ねることで、勾配が消失してしまうことがあります。そこで、層を重ねても勾配が消失しにくい活性化関数として、ReLU関数やその派生であるLeaky ReLU関数が用いられます。また、重みの初期値を適切に設定する、学習率を小さくすることで、勾配消失問題を回避することができます。
ディープニューラルネットワークは、多層パーセプトロンをベースに、様々な構造を持つことができます。これらの構造を持つことで、ディープニューラルネットワークは、画像認識や自然言語処理などの分野で高い精度を出すことができます。ここでは、ディープニューラルネットワークの構造について紹介します。
全結合層は、ニューラルネットワークの中で最も基本的な層です。全結合層は、前の層のすべてのニューロンが次の層のすべてのニューロンと結合しています。そのため、全結合層は、前の層のすべてのニューロンからの入力を受け取り、次の層のすべてのニューロンへ出力します。全結合層は、入力層と出力層の間に複数の中間層を持つことができます。
畳み込みニューラルネットワーク(Convolutional Neural Network: CNN)は、画像認識の分野で高い精度を出すニューラルネットワークの一種です。画像の特徴を抽出する畳み込み層とプーリング層から構成されます。
フィルター演算あるいは畳み込み演算とは、入力データの一部に対してフィルターと呼ばれる小さな行列を適用し、フィルターと入力データの対応する要素の積和を計算する演算です。フィルターは、入力データよりも小さく、入力データの一部に対して適用されます。そのため、フィルター演算の出力は、入力データの一部に対応します。フィルター演算の出力を「特徴マップ」と呼びます。畳み込み層では、複数のフィルターを用いることができます。このとき、畳み込み層の出力は、複数の特徴マップから構成されます。
畳み込みニューラルネットワークを用いた画像認識では、畳み込み層とプーリング層を複数組み合わせて、画像の特徴を抽出します。その後、全結合層を用いて、抽出した特徴を元に画像の分類を行います。
Tensorflow公式によるCNNの実装: https://www.tensorflow.org/tutorials/images/cnn?hl=ja
CNNは入力データの長さ(次元)がすべて統一されていなくてはいけません。そのため、音声や文章といった、隣り合う要素の関連性が強いデータを扱うのに不向きです。これらのデータの特徴は、そのデータの中に、重要な情報がどこにあるかが明確に定まっていないことです。また、与えられるデータの長さも一定ではありません。実際、文章のデータは単語数によって長さが異なります。このような可変長のデータは系列データと呼ばれます。
再帰型ニューラルネットワーク(recurrent neural network: RNN)は、系列的なデータを扱うことができるニューラルネットワークの一種です。RNNは、系列的なデータの中に、重要な情報がどこにあるかを学習することができます。
RNNは、長・短期記憶、ゲート付き再帰ユニットといった様々な構造を持つことができます。これらの構造を持つことで、RNNは時系列データの中に、重要な情報がどこにあるかを自動的に学習することができます。