import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA8 k平均法によるクラスタリング
8.1 クラスタリング
クラスタリングは、類似するデータを類似度や距離などの指標を用いていくつかのグループに分割する手法です。クラスタリングでは、分けられたグループのことをクラスタまたはカテゴリと呼びます。
クラスタリングは顧客を購買履歴などから類似する顧客に分類する顧客セグメンテーション、類似の内容を含む文書を分類するテキストマイニングや、類似の画像を分類する画像認識など、様々な分野で利用されています。また、正常なデータと異常なデータを分類する異常検知にも利用されます。
クラスタリングはデータを自動的に分類する
各クラスタの名前づけは人間が行う
クラスタリングは機械学習の分野では、データがどのグループ(例えば動物の種名や分類群)に属するかという情報を与えず、それ以外の情報を用いて学習することから教師なし学習の一つとして扱われます。クラスタリングの手法はいくつかありますが、ここではk平均法を紹介します。
8.2 k平均法 (k-means法)
k平均法は、データを任意のk個のクラスタに分割する手法です。k平均法は、以下の手順でクラスタリングを行います。
- データをk個のクラスタにランダムに分割する
- 各クラスタの重心を計算する
- 各データを最も近い重心を持つクラスタに再分割する
- 2, 3を繰り返す
- クラスタの再分割が行われなくなったら終了
k平均法を用いてペンギンデータをクラスタリングしてみましょう。
# データの読み込み
penguins = sns.load_dataset("penguins")
# データの確認
penguins.head()| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
データ上にはspecies列が存在するので、ペンギンの身体の部位の大きさや体重、生息地の情報から
# データの前処理
# 欠損値を含む行の削除
penguins = penguins.dropna()
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
penguins["species"] = le.fit_transform(penguins["species"])
# データの分割
X = penguins.drop(columns=["species", "island", "sex"]) # speciesを含め、数値を含まない列を削除
y = penguins["species"]
# データの標準化
scaler = StandardScaler()
X_std = scaler.fit_transform(X)# k平均法の実行
kmeans = KMeans(n_clusters=3, random_state=0)
kmeans.fit(X_std)KMeans(n_clusters=3, random_state=0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KMeans(n_clusters=3, random_state=0)
kの数はいくつにするのがよい?
エルボー法は古い?
8.2.1 結果の確認と比較
データがどのように分類されたか、元のデータと比較して確認してみましょう。
# クラスタリング結果の確認
# クラスタリング結果のラベル
labels = kmeans.labels_
labelsarray([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 0,
2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2,
2, 0, 2, 0, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2,
2, 0, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 0,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 0, 0, 0, 0, 0, 0, 0,
2, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1], dtype=int32)(labels==np.array(y)).sum() / len(labels)0.06606606606606606# Xにラベルを追加
X["cluster"] = np.where(labels == 1, 2, np.where(labels == 2, 1, labels))
# クラスタリング結果のプロット
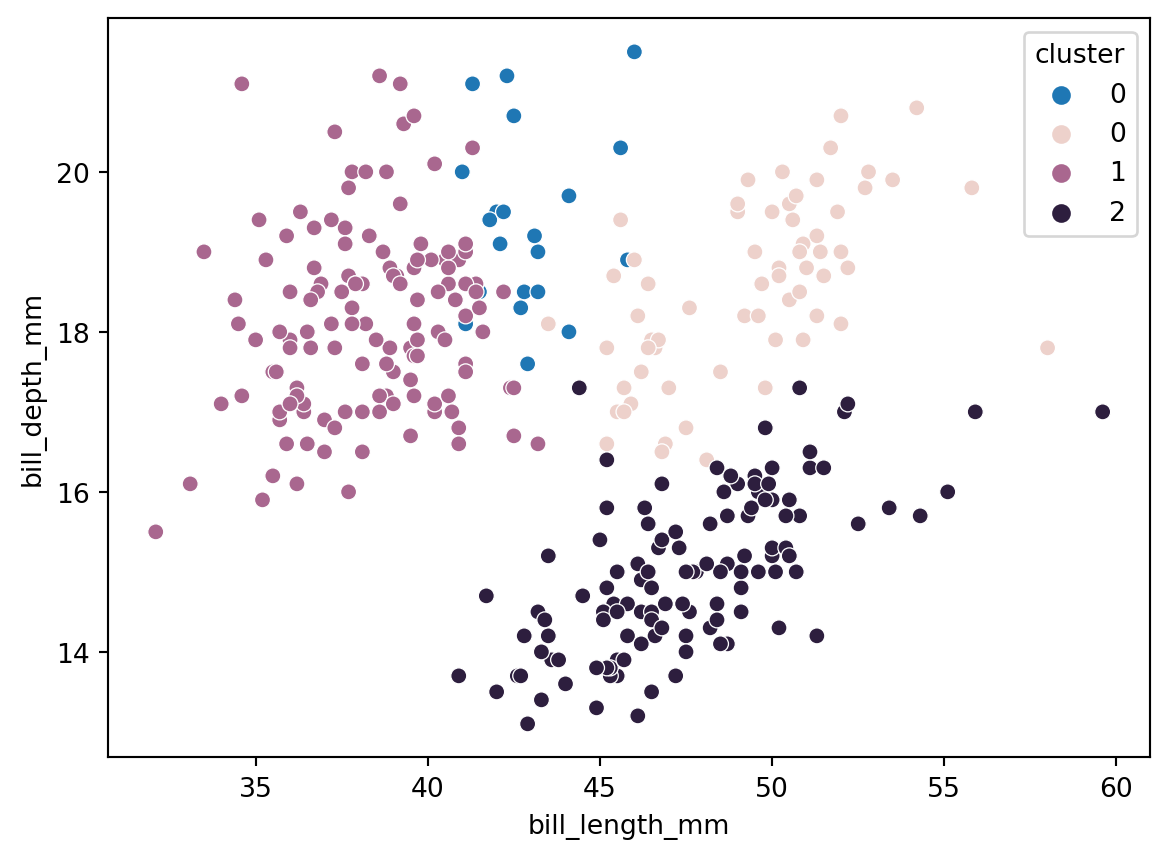
# bill_length vs bill_depth
sns.scatterplot(data=X, x="bill_length_mm", y="bill_depth_mm", hue="cluster")
plt.show()
sns.scatterplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="species")
plt.show()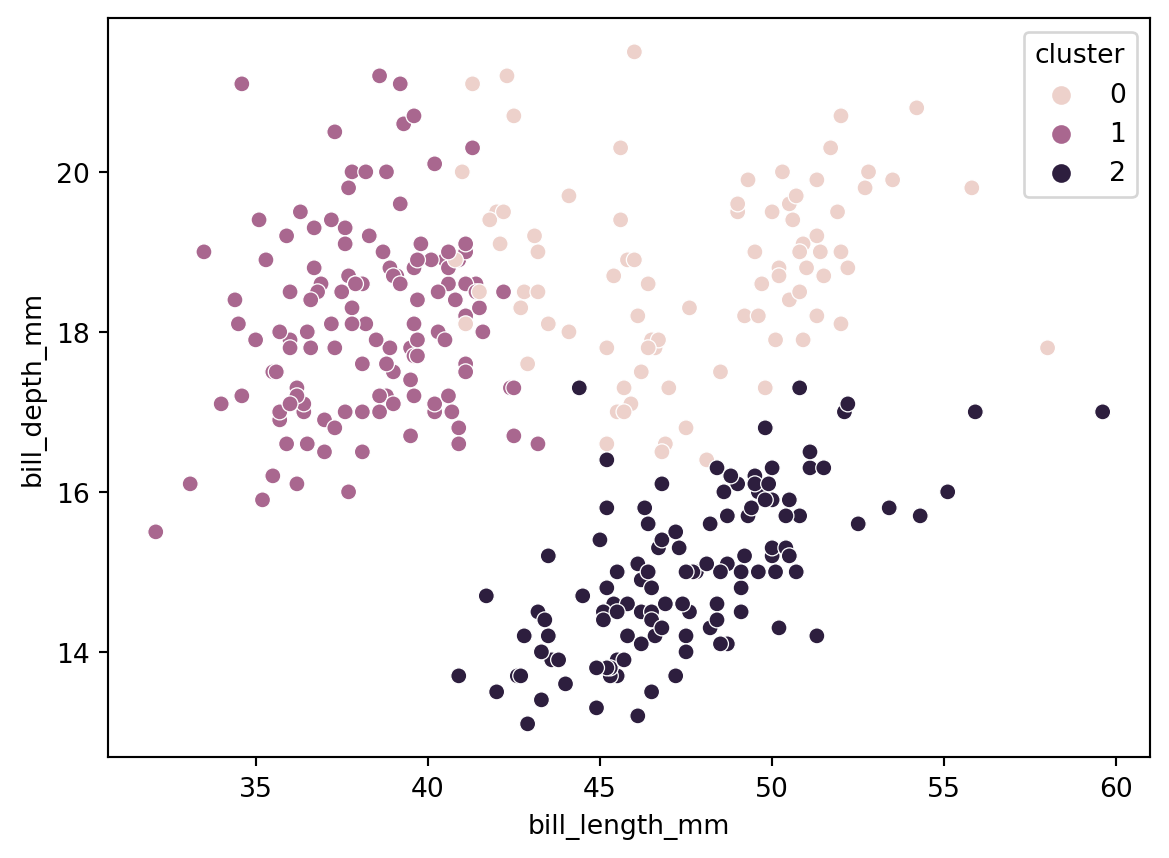

不一致のデータを確認してみましょう。
# 不一致のデータを確認
# sns.scatterplotに追加
sns.scatterplot(data=X[labels == np.array(y)], x="bill_length_mm", y="bill_depth_mm", hue="cluster")
# 不一致のデータを追加
sns.scatterplot(data=X[labels != np.array(y)], x="bill_length_mm", y="bill_depth_mm", hue="cluster")