from pathlib import *
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
p = Path("../")11 電気使用実績を予測するモデルの構築
これまでの講義内容およびAIツールによる補助を用いて、電気使用実績を予測するモデルを構築しましょう。
学習・テストデータのダウンロード
Dropbox からダウンロード
ダウンロードしたファイルを所定のディレクトリに配置してください。
11.1 データの概要
2016年から2018年までの夏期(7月から9月の3ヶ月)における四国エリアの使用状況に加えて、気象庁(観測所: 高松)による気象データを収録しています。
- datetime: 日本標準時での時刻。1時間ごとの記録が行われている。
- usage_GW : 使用状況の実績。単位はGW(ギガワット)。1GBは1000MW。元データでは万kWで記録。
- atmosphere_land_hPa: 現地気圧(hPa)
- precipitation_mm: 降水量(mm)
- temperature_dC: 気温(摂氏)
- humidity_pct: 湿度(%)
df_train = pd.read_csv(p / "week07/input/train.csv", parse_dates=False)
df_test = pd.read_csv(p / "week07/input/test.csv", parse_dates=False)df_train.head(n=5)| datetime | usage_GW | atmosphere_land_hPa | precipitation_mm | temperature_dC | humidity_pct |
|---|---|---|---|---|---|
| 2016-06-30 15:00:00 | 2.53 | 1011.3 | 0 | 23.1 | 96 |
| 2016-06-30 16:00:00 | 2.52 | 1011.1 | 0 | 22.6 | 95 |
| 2016-06-30 17:00:00 | 2.66 | 1011.0 | 0 | 22.1 | 95 |
| 2016-06-30 18:00:00 | 2.86 | 1011.7 | 0 | 21.8 | 96 |
| 2016-06-30 19:00:00 | 2.96 | 1011.7 | 0 | 22.0 | 95 |
| 2016-06-30 20:00:00 | 2.90 | 1011.9 | 0 | 22.0 | 93 |
11.2 データの可視化
# 時系列でのusage_GWの変化を確認
df_train["datetime"] = pd.to_datetime(df_train["datetime"])
# タイムゾーンを日本時間に変換
df_train["datetime"] = df_train["datetime"].dt.tz_convert("Asia/Tokyo")
df_train["year"] = df_train["datetime"].dt.year
g = sns.FacetGrid(df_train, col="year", sharex=False, col_wrap=1)
# 折れ線グラフを描画
g.map(sns.lineplot, "datetime", "usage_GW")
plt.show()これ以外にも、データへの理解を深めるための可視化を行ってみましょう。
11.3 評価指標
モデルの精度を評価するための指標として、二乗平均平方根誤差(RMSE)を用います。
11.4 ベースラインのモデル
教師あり機械学習モデルは一般的に次の手順で構築されます。
参考)第四回スライド
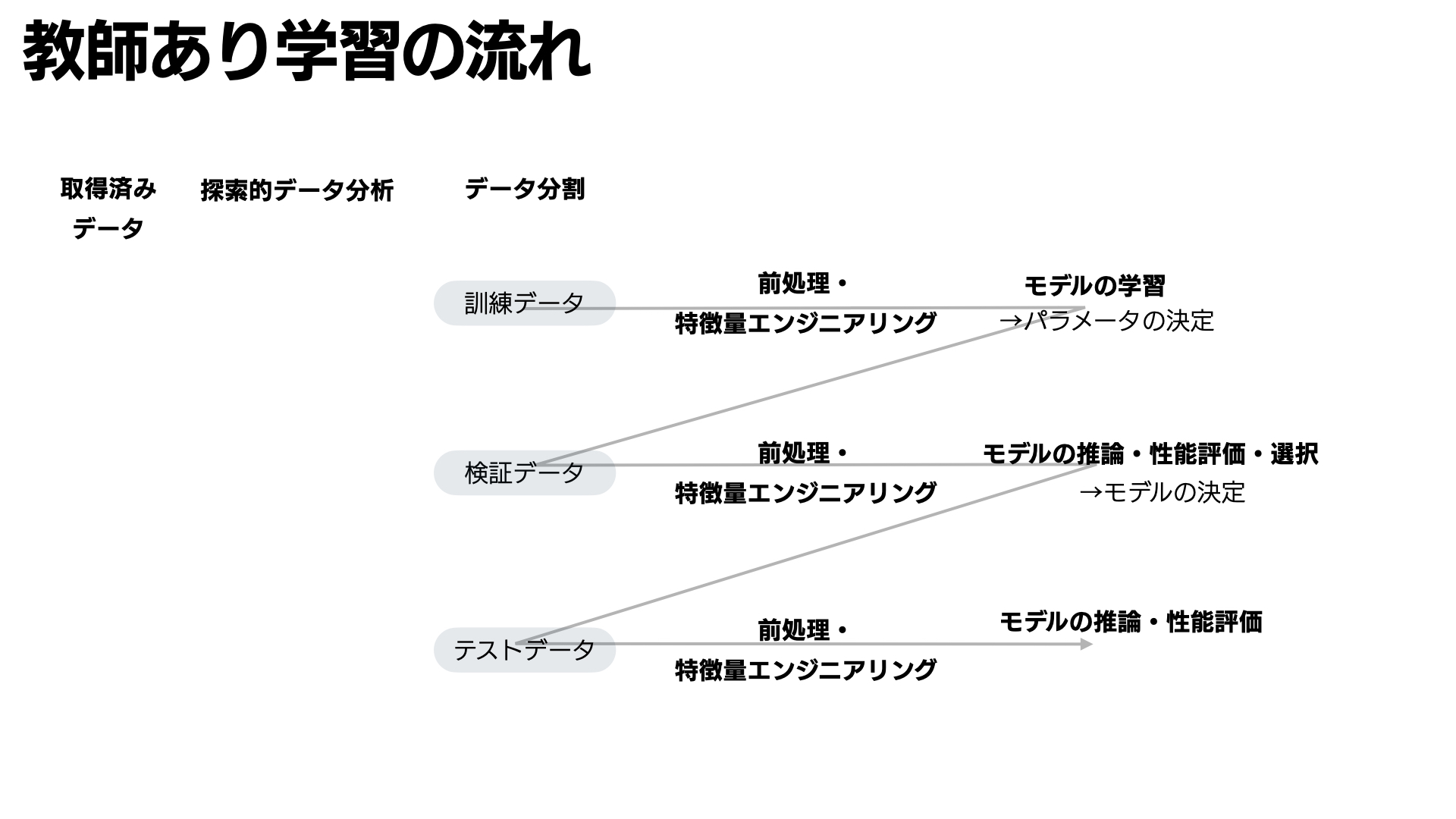
- データ分割
- データの前処理・特徴量エンジニアリング
- モデルの学習
- モデルの性能評価
ここでは機械学習モデルの構築例として、電気使用実績を予測するために気温と降水量を用いた重回帰モデルによるモデルを作成します。このモデルをベースラインとして、他のモデルと比較してみましょう。
11.4.1 データ分割
# 欠損値のある行を削除
df_train_baseline = df_train.dropna()
# 説明変数と目的変数に分割
X = df_train_baseline[["temperature_dC", "precipitation_mm"]]
y = df_train_baseline["usage_GW"]
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=20230529
)11.4.2 前処理・特徴量エンジニアリング
ここでは数値変数の標準化(平均0、分散1への変換)を行います。
Scikit-learnを用いた前処理とモデルの管理はPipelineクラスを用いると便利です。
# 前処理とモデルのパイプラインを作成
# 1/2 前処理を適用する変数と処理内容を指定
numeric_features = ["temperature_dC", "precipitation_mm"]
# パイプラインの作成。stepsには(名前, インスタンス)のタプルを指定する
# standardScalerは平均0、分散1に変換するインスタンス
numeric_transformer = Pipeline(steps=[("scaler", StandardScaler())])
# 2/2 前処理として、数値変数の標準化を指定
preprocessor = numeric_transformer11.4.3 モデルの学習
model = Pipeline(
steps=[("preprocessor", preprocessor), ("regressor", LinearRegression())]
)
model.fit(X_train, y_train)11.4.4 モデルの評価
# テストデータの予測値を計算
y_pred = model.predict(X_test)
# RMSEを計算
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"RMSE: {rmse:.3f}")11.5 モデルの改善例
- 変数の追加
- 交差検証法
- モデルの変更
- 正則化
- ランダムフォレスト
- XGBoost
- LightGBM
- ハイパーパラメータの調整
- 特徴量エンジニアリング… 特に電気使用に影響を与える日付や時間の情報を追加すると良いかもしれません。