tidyデータ: 人間にも機械にも優しいデータの記述形式
データが手に入ってすぐにモデルに利用できることはごく稀で、前処理と呼ばれる作業が必要になります。この作業はデータをモデルに流し込む前段階として必ず必要です。それはデータが欠損値や外れ値といった、扱いに困る値を含んでいることもありますが、多くのデータは入力の形式のまま利用可能ではなく、プログラムが処理しやすい形式へ整形することが求められるためです。
前処理の作業には、このようなデータ整形だけでなく、欠損値の削除や外れ値の削除も含まれます。またモデリングのために余分な列を除外したり、スケーリングの処理を施すなども必要です。そのため前処理を通したデータの質が統計モデリングや機械学習の学習効果に影響を及ぼします。ただしこれらはどのようなデータ、問題に対しても有効なものではなく、利用範囲には幅があります。
ここでは前処理を行わない際の問題点について触れ、tidyデータと呼ばれる形式へのデータ整形方法と一般的な前処理について紹介します。
前処理の必要性
前処理の必要性とその範囲は適用するモデルのタイプによって異なります。
木ベースのモデル(決定木、ランダムフォレスト)では、特徴量を入力とする複数のステップ関数(閾値を超えた場合に1, そうでなければ0に変換する)の組み合わせによって構成されるため変数のスケールの影響を受けません。しかしロジスティック回帰や部分最小二乗法、リッジ回帰や距離を利用するk-means、主成分分析など、多くのモデルは入力のスケールに敏感で、変数間のスケールを揃える必要があります。
前処理の必要性1: 重回帰モデル
df_lp_kanto %>%
lm(posted_land_price ~ distance_from_station + acreage + night_population,
data = .) %>%
tidy()
## # A tibble: 4 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 620112. 37120. 16.7 1.15e-61
## 2 distance_from_station -115. 9.85 -11.7 1.82e-31
## 3 acreage 3.41 2.63 1.29 1.95e- 1
## 4 night_population -0.103 0.0976 -1.05 2.93e- 1
distance_from_staion の影響が一番強く、acreage、night_populationが続きます。しかし
distance_from_staion
の値が大きすぎて他の変数の効果が小さいように見えます。これは元のスケールの影響を受けているためです。
distance_from_staion と acreage
の1は同じ単位ではありません。偏回帰係数を比較する場合、スケーリングを行っておく必要があります。
df_lp_kanto %>%
recipe(posted_land_price ~ distance_from_station + acreage + night_population) %>%
step_center(all_predictors()) %>%
step_scale(all_predictors()) %>%
prep() %>%
juice() %>%
lm(posted_land_price ~ .,
data = .) %>%
tidy()
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## # A tibble: 4 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 415432. 19034. 21.8 8.65e-103
## 2 distance_from_station -226650. 19344. -11.7 1.82e- 31
## 3 acreage 24678. 19058. 1.29 1.95e- 1
## 4 night_population -20325. 19326. -1.05 2.93e- 1
前処理の必要性2: 変数間のスケールが揃わない主成分分析
主成分分析では入力に用いる変数間のスケールが標準化されていることが前提です。それは特徴量空間におけるデータ間を距離を利用するためです。そのため、値の範囲が大きく異なる変数があることでその影響を強く受けます。まずは標準化を行わない場合の結果を見てみましょう。
pca_res <-
prcomp(~ distance_from_station + acreage + night_population,
data = df_lp_kanto,
center = FALSE,
scale. = FALSE)
# 主成分軸上のSDが大きく異なっていることに注意(単位の影響を強く受けている)
pca_res
## Standard deviations (1, .., p=3):
## [1] 326371.254 7270.361 2279.386
##
## Rotation (n x k) = (3 x 3):
## PC1 PC2 PC3
## distance_from_station 0.003184224 0.027579010 -0.99961456
## acreage 0.001558732 0.999618272 0.02758408
## night_population 0.999993716 -0.001645965 0.00314002
# 第1主成分のみで累積寄与率が99%を超える
summary(pca_res)
## Importance of components:
## PC1 PC2 PC3
## Standard deviation 3.264e+05 7.27e+03 2.279e+03
## Proportion of Variance 9.995e-01 5.00e-04 5.000e-05
## Cumulative Proportion 9.995e-01 1.00e+00 1.000e+00
次にあらかじめ標準化したデータを元に主成分分析を行った結果を見ます。
pca_res <-
prcomp(~ distance_from_station + acreage + night_population,
data = df_lp_kanto,
center = TRUE,
scale. = TRUE)
# SDが小さくなる
pca_res
## Standard deviations (1, .., p=3):
## [1] 1.0884300 0.9949390 0.9085244
##
## Rotation (n x k) = (3 x 3):
## PC1 PC2 PC3
## distance_from_station -0.6939753 0.09743571 0.7133755
## acreage -0.2496712 -0.96188952 -0.1115026
## night_population 0.6753241 -0.25548939 0.6918544
# 第2主成分軸まで含めて72%を説明
summary(pca_res)
## Importance of components:
## PC1 PC2 PC3
## Standard deviation 1.0884 0.9949 0.9085
## Proportion of Variance 0.3949 0.3300 0.2751
## Cumulative Proportion 0.3949 0.7249 1.0000
前処理の必要性3: kNN
library(FNN)
set.seed(12)
split_hazard <-
df_hazard_kys %>%
select(hazard, max_elevation, mean_slope_aspect) %>%
drop_na() %>%
rsample::initial_split(strata = "hazard")
df_train <- training(split_hazard)
df_test <- testing(split_hazard)
knn_res <- knn(df_train, df_test, df_train$hazard, k = 2, prob = FALSE)
df_test$predict <- knn_res
attr(knn_res, "nn.index") %>% as.data.frame() %>% as_tibble() %>% .[21, ]
## # A tibble: 1 x 2
## V1 V2
## <int> <int>
## 1 409 619
# get.knn(df_test %>% select_if(is.numeric), k = 2)["nn.index"] %>% as.data.frame() %>% .[397, ]
rec <-
df_train %>%
recipe(hazard ~ .) %>%
step_center(all_predictors()) %>%
step_scale(all_predictors())
df_train_baked <-
rec %>%
prep(training = df_train) %>%
bake(new_data = df_train)
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
df_test_baked <-
rec %>%
prep(training = df_train) %>%
bake(new_data = df_test)
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
knn(df_train_baked, df_test_baked, df_train_baked$hazard, k = 2) %>%
table()
## .
## FALSE TRUE
## 363 42
# p1 <-
# ggplot(df_train, aes(max_elevation, mean_slope_aspect)) +
# geom_point(aes(color = hazard))
#
# # p1 +
# # ylim(range(df_train$max_elevation))
# #
# # plot_grid(p1, p2)
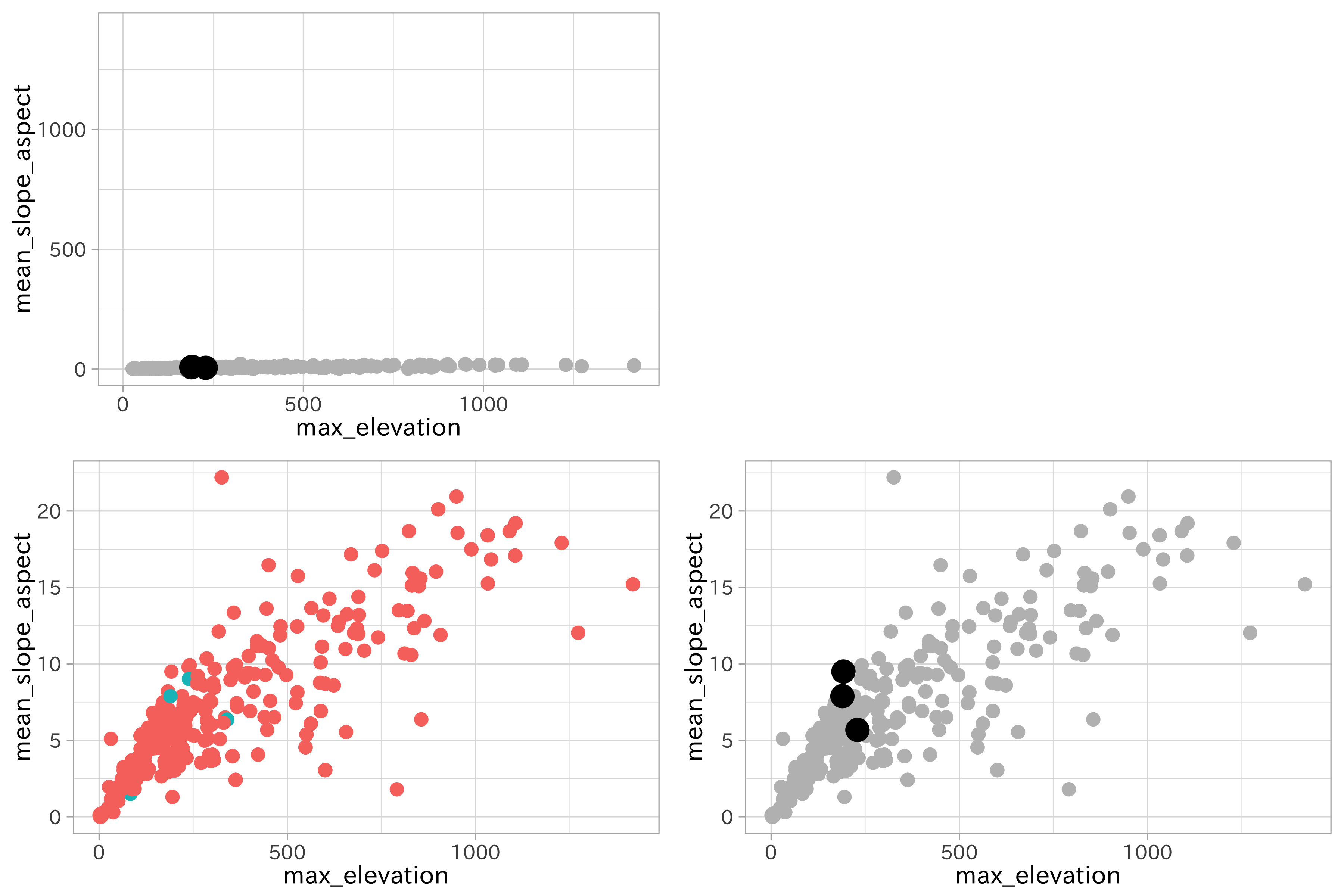
p2 <-
ggplot(df_test,
aes(max_elevation, mean_slope_aspect)) +
geom_point(aes(color = predict))
p3 <-
p2 +
scale_color_manual(values = c("gray", "gray")) +
geom_point(data = df_test %>%
slice(c(397, 147, 271)),
aes(max_elevation, mean_slope_aspect),
# color = "transparent",
size = 3)
# わかりにくいけど、スケールを揃えたら距離が離れる点が近隣として選ばれている
plot_grid(p3 +
ylim(range(df_test$max_elevation)) +
guides(color = FALSE), NULL,
p2 + guides(color = FALSE),
p3 + guides(color = FALSE))
スケーリング処理
変数間のスケールを統一する処理には複数の方法があります。いずれもデータが取りうる値のスケールを変換し、一定の範囲に収める処理を行います。これらは個々の特徴量に対して適用され、後に述べるような対数変換のようにデータの分布を変化させない変換方法になります。
PLSなどで恩恵がありますが
一方でデータが持つ単位を失ってしまうことは、データの解釈を困難にさせます。
これらのスケーリング処理はデータの分布には影響しないことが特徴です。
Min-Maxスケーリング
特徴量の値を0~1の範囲に収める変換をMin-Maxスケーリングと呼びます。
[ \tilde{x} = \frac{x - min(x)}{max(x) - min(x)} ]
Min-Maxスケーリングを行う際は、数値の取り得る値があらかじめわかっているものが望ましいです。データとして存在しない値や外れ値が与えられることで、その値に引っ張られて相対的な差がなくなってしまう恐れがあるからです。
# 地価データの「最寄り駅までの距離」の範囲
lp_dist <- df_lp_kanto$distance_from_station
range(lp_dist)
## [1] 0 24000
lp_dist_minmax <-
scale(lp_dist, center = min(lp_dist), scale = (max(lp_dist) - min(lp_dist)))
range(lp_dist_minmax)
全体を考慮
p1 <-
ggplot(df_lp_kanto, aes(x = 0, y = distance_from_station)) +
geom_violin(color = ds_col(1))
p2 <-
ggplot(data = NULL, aes(0, lp_dist_minmax[, 1])) +
geom_violin(color = ds_col(5)) +
ylab("min_max(lp_dist)")
plot_grid(p1, p2)
- 外れ値が含まれていない場合に良い
- 外れ値の情報を活用したい時には適さない
標準化
標準化 (standardization)… 平均0、分散(標準偏差)1になる。
[ \tilde{x} = \frac{x- mean(x)}{sqrt(var(x))} ]
- 複数の変数に対して行うことで比較が可能になる (平均0, 標準偏差1)
- 範囲スケーリング… 最大値、最小値を利用する
- 共通の「単位」をもつように扱いたい場合に有効
- 距離または内積を利用する –> KNN, SVMs
- ペナルティを課すため –> lasso, ridge
を標準化 (standardization) と呼びます。具体的には変数の取りうる値を平均0、分散1に変換する処理です。
# スケーリングでは分布は変わらない
range(df_lp_kanto$posted_land_price)
p_base <-
df_lp_kanto %>%
ggplot(aes(x = posted_land_price)) +
geom_histogram(bins = 30)
p_base
df_lp_kanto %>%
ggplot(aes(x = scale(posted_land_price, center = TRUE, scale = TRUE)[, 1])) +
geom_histogram(bins = 30)
# hist(df_lp_kanto$posted_land_price)
# hist(scale(df_lp_kanto$posted_land_price)[, 1])
リッジ回帰、主成分分析では変数の標準化が前提となっている
正規化
正規化 (normalization)
取りうる値の範囲が狭くなります。これは外れ値に対して有効な処理と言えます。
体重や身長など、単位が異なる変数を比較する際に役立ちます。
正規化により、取りうる値の範囲が統一されるためです。
データの表現方法を変える
# 地価データにおける駅からの距離
# 平均と分散
df_lp_kanto %>%
summarise(mean = mean(distance_from_station),
sd = sd(distance_from_station))
## # A tibble: 1 x 2
## mean sd
## <dbl> <dbl>
## 1 1566. 1965.
# center, scale引数はいずれも既定でTRUEです
lp_dist_scaled <-
c(scale(df_lp_kanto$distance_from_station, center = TRUE, scale = TRUE))
mean(lp_dist_scaled) # 限りなく0に近くなる
## [1] 3.056636e-17
sd(lp_dist_scaled) # 分散は1
## [1] 1
diff(range(lp_dist))
## [1] 24000
median(lp_dist)
## [1] 1000
diff(range(c(scale(lp_dist))))
## [1] 12.215
標準地からの鉄道駅までの距離の中央値は900で、最小値は0 (近接の場合は0が与えられる)、最大値は24000です。この特徴量を標準化するとその差は14.02にまで縮まります。
距離の
これらの手法は、対数変換と異なりデータの分布には影響しないことが特徴です。
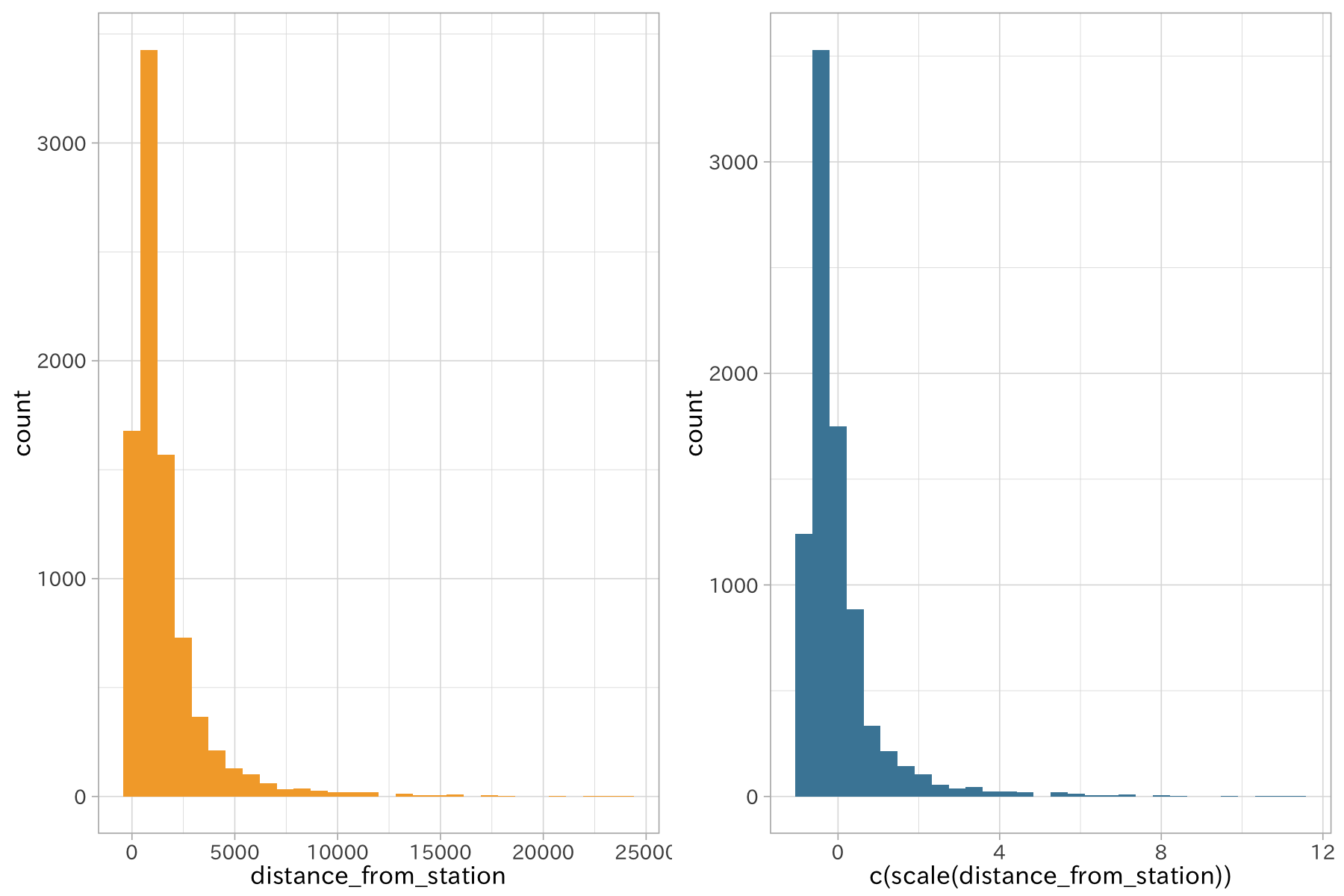
p1 <-
ggplot(df_lp_kanto,
aes(distance_from_station)) +
geom_histogram(bins = 30, fill = ds_col(1))
p2 <-
ggplot(df_lp_kanto,
aes(c(scale(distance_from_station)))) +
geom_histogram(bins = 30, fill = ds_col(5)) +
scale_fill_identity() + aes(fill = ds_col(1))
plot_grid(p1, p2, ncol = 2)
データ浄化
- 情報を含まない列の削除
- 分散が0の説明変数 (constant cols)
- 重複した説明変数を一つに
- 多重共線性
- 相関係数が1である説明変数の組 (perfectly correlated cols) をユニークに
- データリーク
データセットに含まれる列のうち、attribute_change_forest_law と
attribute_change_parks_law は論理型の変数でありながら1値しか持たない(分散が0)ものでした。
外れ値
欠損処理
不要な列の削除
特徴量選択の文脈においてはフィルタ法
… 情報量がない列
単一の変数についてと、変数間の関係をそれぞれ調べることが重要になります。
もう一度データを確認しておきましょう。
- 変数内
- 単一の値のみが含まれる変数 (分散0)
- 変数間
- 同一の値の組み合わせ
- 相関係数が1になる
- データセット全体
- 完全に欠損する行・列
df_lp_kanto %>% skimr::skim_to_list()
## $character
## # A tibble: 14 x 8
## variable missing complete n min max empty n_unique
## * <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 .prefecture 0 8476 8476 3 4 0 7
## 2 administrative_area_c… 0 8476 8476 5 5 0 329
## 3 building_structure 220 8256 8476 2 8 0 130
## 4 configuration 7454 1022 8476 2 3 0 2
## 5 current_use 0 8476 8476 2 14 0 70
## 6 fire_area 4859 3617 8476 2 2 0 2
## 7 forest_law 8450 26 8476 3 3 0 1
## 8 name_of_nearest_stati… 0 8476 8476 1 14 0 1481
## 9 parks_law 8465 11 8476 7 7 0 2
## 10 proximity_with_transp… 8308 168 8476 2 6 0 3
## 11 surrounding_present_u… 0 8476 8476 15 22 0 4397
## 12 urban_planning_area 0 8476 8476 2 3 0 4
## 13 usage_description 7552 924 8476 1 8 0 40
## 14 use_district 515 7961 8476 2 3 0 12
##
## $integer
## # A tibble: 6 x 12
## variable missing complete n mean sd p0 p25 p50 p75 p100
## * <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 .row_id 0 8476 8476 " 18… " … 13534 1640… " 18… " 20… " 23…
## 2 acreage 0 8476 8476 " … " … 46 " 1… " … " … "413…
## 3 distanc… 0 8476 8476 " 1… " … 0 " 5… " 1… " 1… " 24…
## 4 number_… 0 8476 8476 " … " … 0 " … " … " … " …
## 5 number_… 0 8476 8476 " … " … 0 " … " … " … " …
## 6 posted_… 0 8476 8476 "415… 1766… 613 "599… "155… "308… " …
## # … with 1 more variable: hist <chr>
##
## $logical
## # A tibble: 17 x 6
## variable missing complete n mean count
## * <chr> <chr> <chr> <chr> <chr> <chr>
## 1 attribute_change_acreage 0 8476 8476 "0.003… FAL: 8450, TRU:…
## 2 attribute_change_address 0 8476 8476 "0.007… FAL: 8411, TRU:…
## 3 attribute_change_buildi… 0 8476 8476 0.00024 FAL: 8474, TRU:…
## 4 attribute_change_buildi… 0 8476 8476 "0.008… FAL: 8406, TRU:…
## 5 attribute_change_curren… 0 8476 8476 "0.008… FAL: 8402, TRU:…
## 6 attribute_change_distan… 0 8476 8476 "0.005… FAL: 8431, TRU:…
## 7 attribute_change_fire_a… 0 8476 8476 "0.007… FAL: 8417, TRU:…
## 8 attribute_change_floor_… 0 8476 8476 0.00024 FAL: 8474, TRU:…
## 9 attribute_change_forest… 0 8476 8476 "0 … FAL: 8476, NA: 0
## 10 attribute_change_parks_… 0 8476 8476 "0 … FAL: 8476, NA: 0
## 11 attribute_change_suppli… 0 8476 8476 "0.005… FAL: 8429, TRU:…
## 12 attribute_change_urban_… 0 8476 8476 0.00012 FAL: 8475, TRU:…
## 13 attribute_change_use_di… 0 8476 8476 0.00012 FAL: 8475, TRU:…
## 14 common_surveyed_position 0 8476 8476 "0.071… FAL: 7870, TRU:…
## 15 gas_facility 0 8476 8476 "0.78 … TRU: 6616, FAL:…
## 16 sewage_facility 0 8476 8476 "0.92 … TRU: 7775, FAL:…
## 17 water_facility 0 8476 8476 "0.99 … TRU: 8427, FAL:…
##
## $numeric
## # A tibble: 8 x 12
## variable missing complete n mean sd p0 p25 p50 p75 p100
## * <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 .latitu… 0 8476 8476 " … " … " 3… " … " … " … " …
## 2 .longit… 0 8476 8476 " … " … " 13… " … " 1… " … " 1…
## 3 attribu… 0 8476 8476 " … " … " … " … " … " … " …
## 4 buildin… 0 8476 8476 " … " … " … " … " … " … " …
## 5 depth_r… 0 8476 8476 " … " … " … " … " … " … " …
## 6 floor_a… 0 8476 8476 " … " 1… " … " … " 2… " … " 13…
## 7 frontag… 0 8476 8476 " … " … " … " … " … " … " …
## 8 night_p… 0 8476 8476 2594… "2e+… "321… "118… "2e+… "341… "9e+…
## # … with 1 more variable: hist <chr>
attribute_change_forest_law と attribute_change_parks_law
の列は二値データを持つことができる変数ですが、いずれも一つの値しか記録されていません。変数内での分散は0となり、情報を持っていないのと同義です(標準化も適用できません)。そのためこれらの値はモデル構築の前にデータから削除しても問題ないと考えられます。
情報量がゼロ(分散ゼロ)
数値データでは稀ですが、論理値変数やカテゴリ変数に潜んでいる、こうした1種類の値しか取らないデータは除外しましょう。
# 分散ゼロ
scale(c(0, 0, 0), scale = TRUE)
## [,1]
## [1,] NaN
## [2,] NaN
## [3,] NaN
## attr(,"scaled:center")
## [1] 0
## attr(,"scaled:scale")
## [1] 0
df_lp_kanto_clean <-
df_lp_kanto %>%
verify(ncol(.) == 45) %>%
as.data.frame() %>%
remove_constant() %>%
as_tibble() %>%
verify(ncol(.) == 43)
dim(df_lp_kanto_clean)
## [1] 8476 43
このデータの場合、これ以外で単独の値しか持たない変数はありませんでした。
どうやら違うようです。
df_lp_kanto %>%
distinct(attribute_change_urban_planning_area,
attribute_change_use_district)
## # A tibble: 3 x 2
## attribute_change_urban_planning_area attribute_change_use_district
## <lgl> <lgl>
## 1 FALSE FALSE
## 2 FALSE TRUE
## 3 TRUE FALSE
分散が0に近い変数を削除する
変数の数は減りますが、重要な変数を削除してしまう恐れがあります。この作業は慎重に
dim(df_lp_kanto_clean)
## [1] 8476 43
nzv_filter <-
df_lp_kanto_clean %>%
recipe(~ .) %>%
step_nzv(all_predictors())
filtered_te <-
nzv_filter %>%
prep() %>%
juice() %>%
verify(ncol(.) == 28)
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
dim(filtered_te)
## [1] 8476 28
# 削除される列がどのような値を持っているか確認して
df_lp_kanto_clean %>%
select(names(df_lp_kanto_clean)[!names(df_lp_kanto_clean) %in% names(filtered_te)]) %>%
glimpse()
## Observations: 8,476
## Variables: 15
## $ usage_description <chr> "別荘", NA, NA, "別荘", NA, …
## $ attribute_change_supplied_facility <lgl> FALSE, FALSE, FALSE, FAL…
## $ water_facility <lgl> TRUE, TRUE, TRUE, TRUE, …
## $ forest_law <chr> NA, NA, NA, NA, NA, NA, …
## $ attribute_change_floor_area_ratio <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_selected_land_status <dbl> 1, 1, 1, 1, 1, 1, 1, 1, …
## $ attribute_change_address <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_acreage <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_current_use <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_building_structure <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_distance_from_station <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_use_district <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_fire_area <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_urban_planning_area <lgl> FALSE, FALSE, FALSE, FAL…
## $ attribute_change_building_coverage <lgl> FALSE, FALSE, FALSE, FAL…
# 重要ではなさそうなので削除
df_lp_kanto_clean <- filtered_te
# 変わらん(正しい)
# df_hazard_kys %>%
# as.data.frame() %>%
# remove_empty("cols") %>%
# dim()
相関係数が高い変数を
多重共線性の問題を引き起こします。
いずれかの変数だけを利用するようにしましょう。
library(GGally)
## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2
df_lp_kanto_clean %>%
select(-starts_with(".")) %>%
select_if(is.numeric) %>%
corrr::correlate()
##
## Correlation method: 'pearson'
## Missing treated using: 'pairwise.complete.obs'
## # A tibble: 10 x 11
## rowname posted_land_pri… distance_from_s… acreage depth_ratio
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 posted… NA -0.126 0.00819 0.0375
## 2 distan… -0.126 NA 0.0468 -0.0646
## 3 acreage 0.00819 0.0468 NA 0.00383
## 4 depth_… 0.0375 -0.0646 0.00383 NA
## 5 number… 0.438 -0.228 -0.0135 0.102
## 6 number… 0.543 -0.138 0.0164 0.0428
## 7 buildi… 0.212 -0.206 -0.00184 0.294
## 8 fronta… 0.0486 -0.0185 0.0330 -0.220
## 9 floor_… 0.473 -0.228 0.00763 0.223
## 10 night_… 0.0103 -0.172 -0.0202 0.0211
## # … with 6 more variables: number_of_floors <dbl>,
## # number_of_basement_floors <dbl>, building_coverage <dbl>,
## # frontage_ratio <dbl>, floor_area_ratio <dbl>, night_population <dbl>
library(GGally)
df_lp_kanto_clean %>%
select(-starts_with(".")) %>%
select_if(is.numeric) %>%
corrr::correlate()
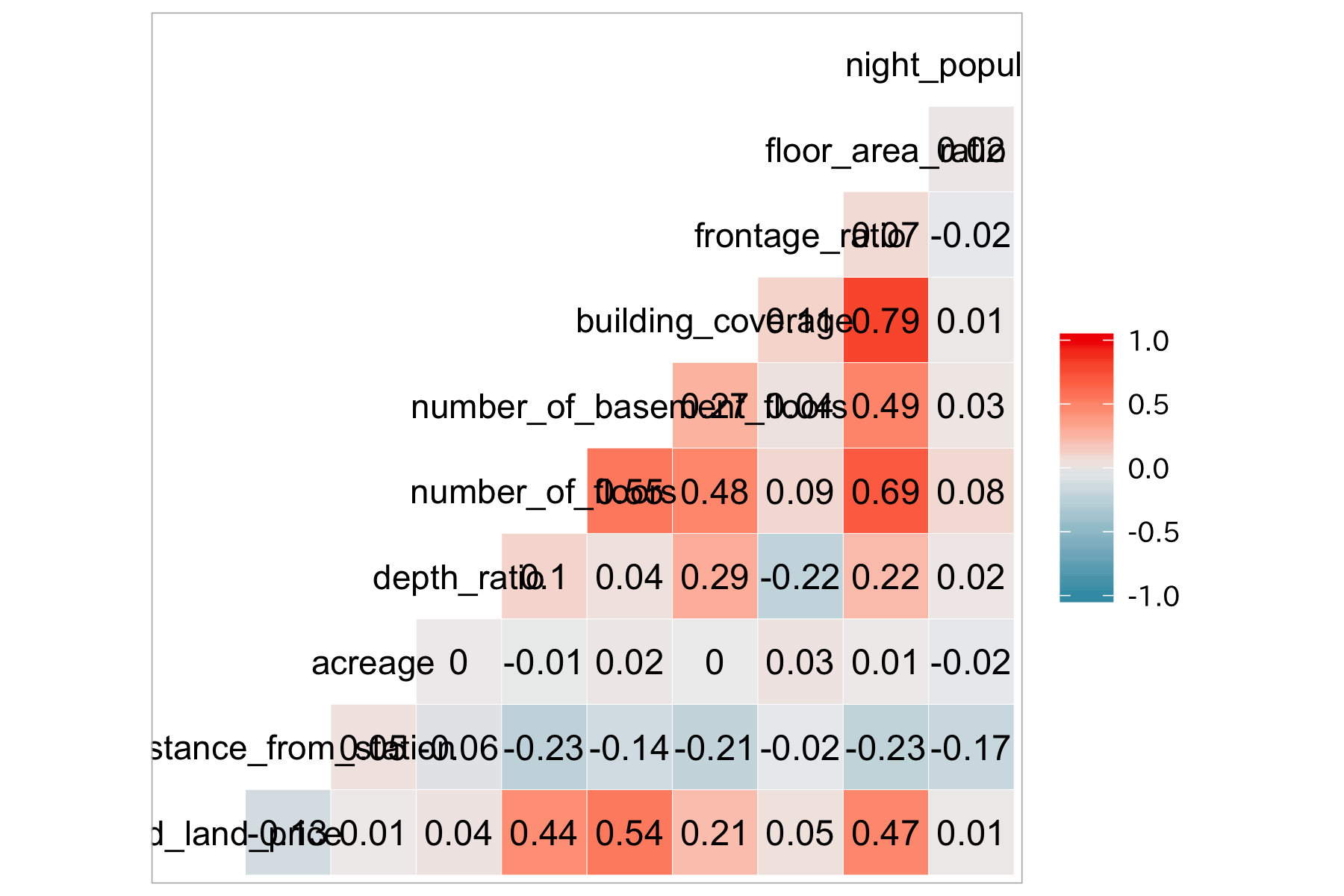
# 最大 0.79... building_coverage - floor_area_ratio
df_lp_kanto_clean %>%
select(-starts_with(".")) %>%
select_if(is.numeric) %>%
ggcorr(label = TRUE, label_round = 2)
# df_lp_kanto では不適切
df_lp_kanto_clean %>%
recipe(~ .) %>%
step_corr(all_numeric(), -starts_with("."), threshold = 0.9) %>%
prep() %>%
juice() %>%
verify(ncol(.) == 28L)
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## # A tibble: 8,476 x 28
## .row_id .prefecture administrative_… posted_land_pri… name_of_nearest…
## <int> <fct> <fct> <int> <fct>
## 1 13534 群馬県 10425 4150 万座・鹿沢口
## 2 13604 群馬県 10426 39000 長野原草津口
## 3 13605 群馬県 10426 56800 長野原草津口
## 4 13613 群馬県 10424 2700 羽根尾
## 5 13620 群馬県 10424 12100 羽根尾
## 6 13621 群馬県 10426 29800 長野原草津口
## 7 13640 群馬県 10424 16400 群馬大津
## 8 13755 群馬県 10382 17400 下仁田
## 9 13758 群馬県 10382 25500 下仁田
## 10 13765 群馬県 10382 23300 下仁田
## # … with 8,466 more rows, and 23 more variables:
## # distance_from_station <int>, acreage <int>, current_use <fct>,
## # building_structure <fct>, gas_facility <lgl>, sewage_facility <lgl>,
## # proximity_with_transportation_facility <fct>, depth_ratio <dbl>,
## # number_of_floors <int>, number_of_basement_floors <int>,
## # use_district <fct>, building_coverage <dbl>, configuration <fct>,
## # surrounding_present_usage <fct>, fire_area <fct>,
## # urban_planning_area <fct>, parks_law <fct>, frontage_ratio <dbl>,
## # floor_area_ratio <dbl>, common_surveyed_position <lgl>,
## # .longitude <dbl>, .latitude <dbl>, night_population <dbl>
# 閾値を低くする
df_lp_kanto_clean %>%
recipe(~ .) %>%
step_corr(all_numeric(), -starts_with("."), threshold = 0.75) %>%
prep() %>%
juice() %>%
verify(ncol(.) == 27L)
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## Warning: All elements of `...` must be named.
## Did you want `data = c(type, role, source)`?
## # A tibble: 8,476 x 27
## .row_id .prefecture administrative_… posted_land_pri… name_of_nearest…
## <int> <fct> <fct> <int> <fct>
## 1 13534 群馬県 10425 4150 万座・鹿沢口
## 2 13604 群馬県 10426 39000 長野原草津口
## 3 13605 群馬県 10426 56800 長野原草津口
## 4 13613 群馬県 10424 2700 羽根尾
## 5 13620 群馬県 10424 12100 羽根尾
## 6 13621 群馬県 10426 29800 長野原草津口
## 7 13640 群馬県 10424 16400 群馬大津
## 8 13755 群馬県 10382 17400 下仁田
## 9 13758 群馬県 10382 25500 下仁田
## 10 13765 群馬県 10382 23300 下仁田
## # … with 8,466 more rows, and 22 more variables:
## # distance_from_station <int>, acreage <int>, current_use <fct>,
## # building_structure <fct>, gas_facility <lgl>, sewage_facility <lgl>,
## # proximity_with_transportation_facility <fct>, depth_ratio <dbl>,
## # number_of_floors <int>, number_of_basement_floors <int>,
## # use_district <fct>, building_coverage <dbl>, configuration <fct>,
## # surrounding_present_usage <fct>, fire_area <fct>,
## # urban_planning_area <fct>, parks_law <fct>, frontage_ratio <dbl>,
## # common_surveyed_position <lgl>, .longitude <dbl>, .latitude <dbl>,
## # night_population <dbl>
テキストデータの前処理については別の章で解説します。
次元削減と特徴量抽出
元データの情報を可能な限り多く含んだ状態を維持しつつ、新たな特徴量を抽出するプロセスとして次元削減があります。主成分分析に代表されるように、これらの手法は高次元のデータのばらつきをより失わない方法で圧縮します。。特に主成分分析では高次元空間上に直交するベクトルを特徴量(成分)とすることから、入力に相関のある特徴量を与えても無相関の特徴量を得ることが可能です。
なお主成分分析は変数のスケールの影響を強く受けます。実行する前にはスケーリング処理を行うようにしましょう。主成分分析を含めた次元削減の実行については次元削減で解説します。
関連項目
参考文献
- Max Kuhn and Kjell Johnson (2013). Applied Predictive Modeling. (Springer)
- 本橋智光 (2018). 前処理大全 (技術評論社)
- Max Kuhn and Kjell Johnson (2019).Feature Engineering and Selection: A Practical Approach for Predictive Models (CRC Press)