データ分析のプロセス
課題や目標が設定され、動き出したデータ分析のプロジェクトは、いつも直線に進んでいく訳ではありません。最初の段階として、利用するデータに不備があったがために出鼻を挫かれることもあります。それが済んだらデータを整理・整形する作業が発生します。多くのデータは入力された状態でコンピュータが利用しやすい形式とは異なっているためです。
そしてここからがさらに骨の折れる作業です。本書のテーマもここの作業段階での話となります。具体的にはデータの加工・変形と可視化、そしてモデルの構築です。これらの作業は互いに繋がっている点に注意してください。加えて、これらの作業は反復的に行われることが前提です。一般的にデータをモデルに投入する前の加工作業を前処理と呼びますが、複数のモデルを構築し、調整や検証をすることになるでしょう。この段階の作業の詳細は次の章で解説します。
下記の図は典型的なデータ分析のワークフローを描いたものです。もちろん常にこの通りに事が運ぶわけではありません。繰り返しの数にも差がありますし、後戻りも必要になるでしょうが、これらの過程が欠けることはほぼないでしょう。モデルの実行以外にも、多岐に渡る作業があります。また、モデル開発後の作業も大事です。可視化やモデルの実行結果は垂れ流しにしておくわけには行きません。どのような手段にせその結果を伝達することが必要になります。
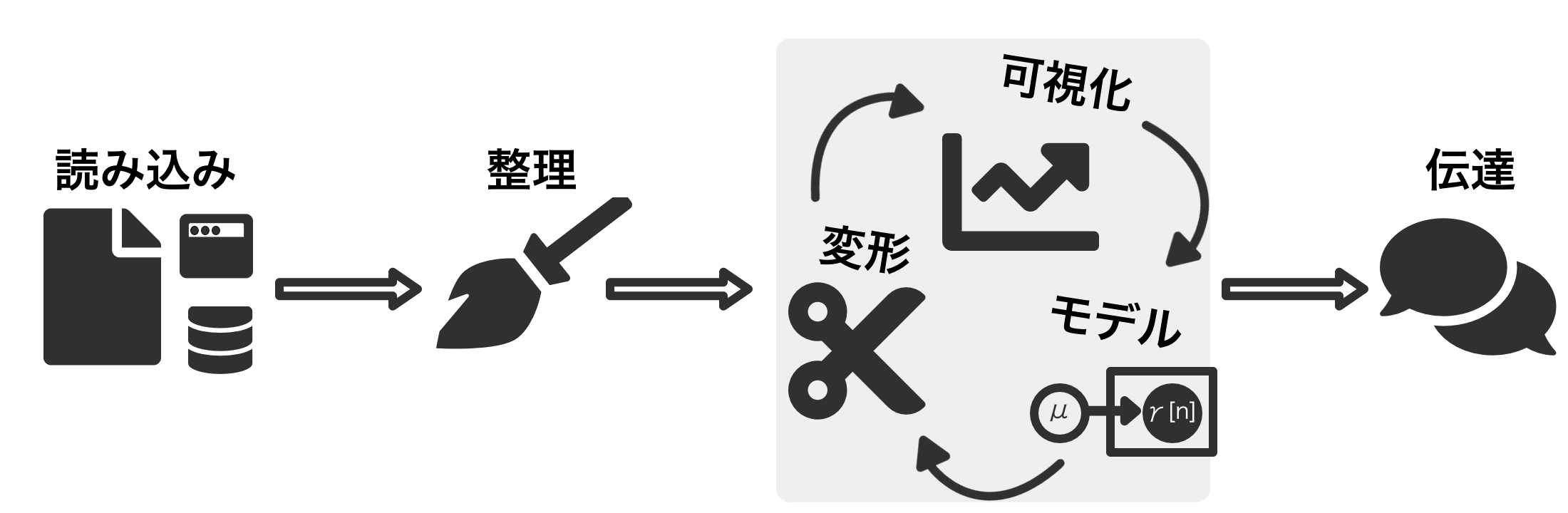
ここでは全体的なデータ分析のワークフローを俯瞰して考えてみることにします。まず、データが用意されたら問題設定を明らかにすること、そして問題解決のためのモデルについて考える必要があります。このデータを使って何を明らかにすることが目的でしょう。またその結果をどのように使い、何を得たいのかを明らかにしておくことはモデルの開発にとっても重要です。どの程度の精度が望まれているのか、計算リソースはどの程度か、運用時にはどのような懸念事項が考えられるか、考えることは尽きません。
問題設定とモデル
- モデルに応じて、データの分布などに仮定をおいているものがある
- 仮定に合わないデータを与えた場合、適切な結果が得られない恐れがある
- e.g. 線形モデル… 誤差が等分散正規分布であることを仮定
- 正規分布に従わない場合は一般化線形モデルを利用するなどの対処
- e.g. K-meansクラスタリング… 各クラスタが同じ大きさ
- クラスタの大きさに偏りがある場合には混合正規分布の利用を検討
- ノーフリーランチ定理
- あらゆる問題で性能の良い万能なモデル・アルゴリズムは存在しない
- 問題・目的に適したモデルを選択することが重要
ここでは各手法についての説明は行いません。データ分析、機械学習についての専門書は多く出版されているため、巻末の参考文献の一覧をご覧ください。
データの持つ意味
データはいくつかの種類に分けられます。これらはデータ型と呼ばれ、データ型に応じてプログラムで実行可能な処理が異なります。一般的なものが論理値、数値、文字列です。一方でいくつかのデータ型が基本的なデータ型の拡張としてあります。これらは日付・時間、空間情報のためのデータ型です。これらのデータ型はそれぞれで独特の扱いが必要になります。
- データ型に基づく分類
- 数値… 量を表現する
- カテゴリ… 決められた選択肢の中から項目を示す
- 順序つき
- 論理値… 二値によって表現される
- 文字列
- 特殊系… ドメイン知識が必要・あると役立つ応用的な特徴量エンジニアリング
- 日付・時間
- 地理空間・座標
- 画像
尺度を元にした分類
データの変数は大きく質的変数と量的変数に区別されます。さらに質的変数は名義尺度と順序尺度に、量的変数は間隔尺度と比例尺度に分かれます。それぞれの尺度は次のように定義されます。
- 名義尺度… 名前などの固有の識別子を与えることで、他の区別可能な性質を持つもの。
- 順序尺度… 順序に意味があり、並べた時に相互の関係がわかるもの。明るさや強さなど、程度を示す。
- 間隔尺度… 比べた時に数値間の順序があるもの。等間隔に数値が与えられるもの。気温や階数など、差や平均を議論する。
- 比例尺度… 数量が与えられ、さまざまな数値演算が可能。
情報をデータとして利用可能にする
データをモデルに当てはめる、アルゴリズムによる計算を実行するには数値化が必要になります。言い換えるとデータをモデルが識別可能な形式に処理する必要があります 。多くのデータは数値化されていますが、ログデータ、文書をコンピュータで利用可能にした段階では数値化されていないことが多いです。画像データもバイナリファイルなので元のデータは数値ではないはずです。
また、すでに数値となっているデータに対しても、より良い特徴量として扱うために変換処理を加えることがあります。これらはモデルにデータの良い特徴を与えるための作業であり、データの前処理や特徴量エンジニアリングの作業です。各種のデータに対して、特徴量エンジニアリングが求められる状況は次のものがあります。
- 表形式のデータでは、行に観測が記録され、複数の列からなる特徴量が含まれる
- 一つの文書や一回のつぶやきが観測され、フレーズや単語が特徴になる
- 画像データでは、色や線の情報を特徴量として利用する
- 機械学習モデルでは数値データを入力の前提にしているものが多い
予測モデルの種類(線形モデル、KNN、ニューラルネットワークなどのモデルか決定木やランダムフォレストを利用する木ベースのモデルか)とデータの種類に応じて適用する前処理、特徴量エンジニアリングが異なります。
特徴量エンジニアリング
特徴量エンジニアリングは、モデルに適した形(数値)への変換と述べました。では前処理との違いは何でしょうか。前処理はクレンジングとも呼ばれ、基本的には減算のプロセスです。データから不要な情報を削除したり、欠損や異常値を取り除いたりします。対する特徴量エンジニアリングは変数を減らすこともありますが情報を減らすことはほぼありません。本書では特徴量エンジニアリングは(主に)加算のプロセスとして前処理と区別することにします。
また特徴量エンジニアリングは、よりモデルの性能に直結する作業です。それは既存の変数を加工することでその情報を強調することができるためです。一般的なデータ分析モデルで有効な特徴量エンジニアリングの手法がいくつかあります。これらは「守り」の特徴量エンジニアリングと考えられます。有効な、と言いましたが一方で必要な処理を施していない場合にはモデルの性能が低いままのものがあるためです。一方でドメイン知識と呼ばれるデータの背景を理解している場合に活用可能な情報を組み込むことも可能です。これは「攻め」の特徴量エンジニアリングです。すべての人がドメイン知識をもっている訳ではありません。「攻め」の特徴量エンジニアリングは、データとモデルの関係についての背景知識があってこその武器となるのです。
どうして特徴量エンジニアリングが必要なのか
どうして特徴量エンジニアリングが必要なのかを考える前に、精度の高いモデルとは何かを考えることにします。精度の高いモデルとは、入力に与えられた変数から出力変数の値を予測・分類する能力が高いモデルです。そのためには、モデルの学習段階で価値のある特徴量を作成し、ノイズをもたらす特徴量を除去することが重要です。特徴量はモデルの学習に利用され、モデルの性能に大きな影響を及ぼすことを頭から忘れないようにしましょう。
有名な言葉で “Garbage in, garbage out (GIGO)” があります。分析に利用するデータの一次的な状態を生データと呼ぶことがりますが、生データのままでは特徴を表現することが難しいことがあります。生データを分析モデルに投入しても良い結果が得られる見込みは低いでしょう。また、データを数値的に表現する方法はいくらも存在するため、適当な変換を施したモデルを作ることも容易です。しかし、モデルのパターンを掴んだ、良い特徴量を見つけるのは大変な作業になります。特徴量エンジニアリングによってデータのパターンを見出しやすくするようにするのが我々の仕事になります。
特徴量エンジニアリングの作業を要約すると次の項目に分けて考えることができます。
- 特徴をモデルに落とし込む
- 代表的な変数を選ぶこと、集約する
- モデルのパターンを表現する方法を選び出す
特徴量エンジニアリング以外で重要なこと
- 変数重要度、特徴量選択
- データセットの分割
- モデル性能評価の指標
- パラメータ調整… グリッドサーチ、ベイジアン最適化など