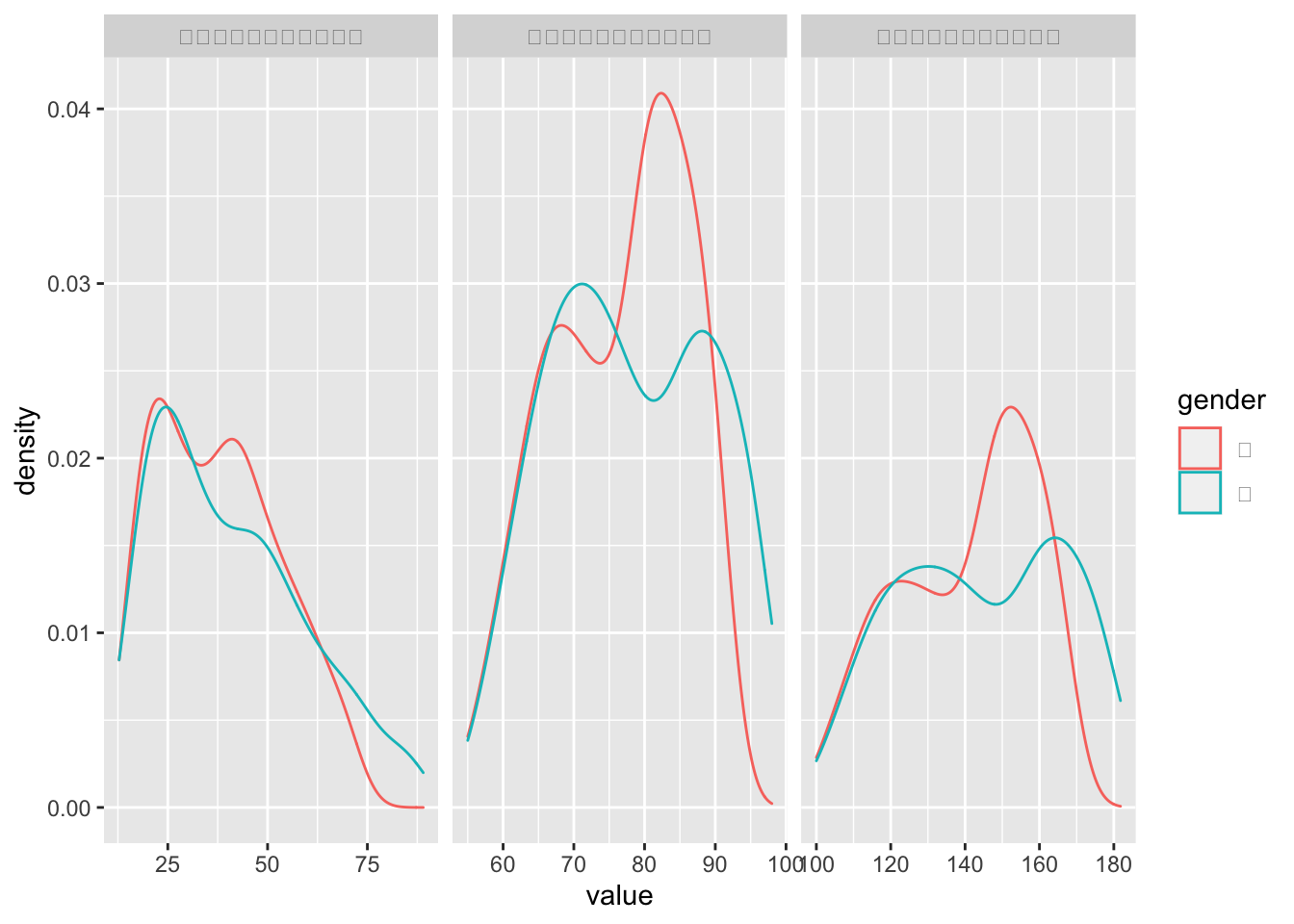
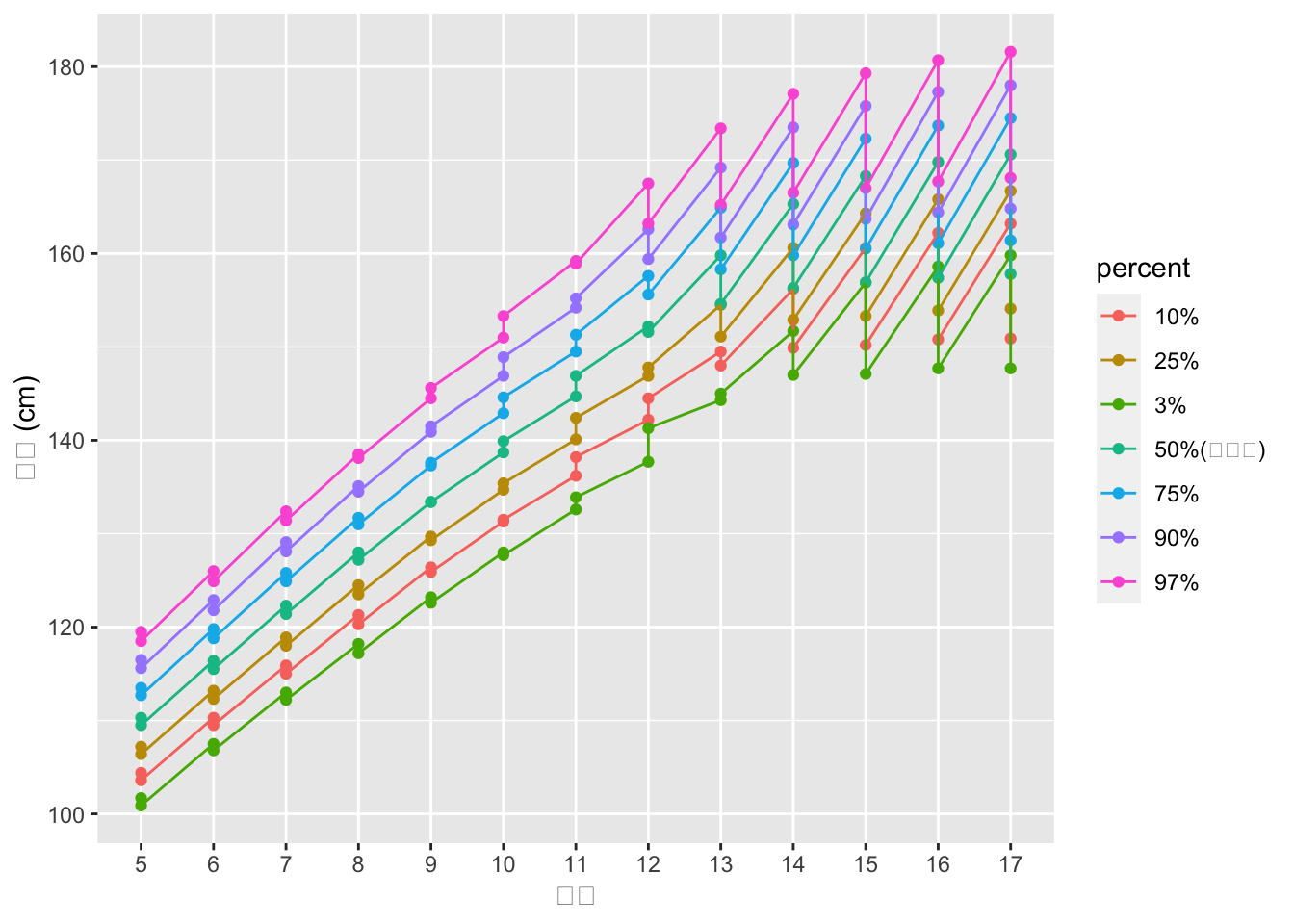
Rows: 367
Columns: 24
$ 年月日 <chr> NA, NA, "2017/1/1", "2017/1/2", "2017/1/3", "2…
$ `平均気温(℃)...2` <dbl> NA, NA, 4.0, 3.9, 4.8, 5.7, 3.6, 0.7, 0.8, 3.0…
$ `平均気温(℃)...3` <chr> NA, "品質情報", "8", "8", "8", "8", "8", "8", …
$ `平均気温(℃)...4` <chr> NA, "均質番号", "1", "1", "1", "1", "1", "1", …
$ `最低気温(℃)...5` <dbl> NA, NA, -3.0, -1.4, -2.2, -2.4, -3.2, -5.6, -5…
$ `最低気温(℃)...6` <chr> NA, "品質情報", "8", "8", "8", "8", "8", "8", …
$ `最低気温(℃)...7` <chr> NA, "均質番号", "1", "1", "1", "1", "1", "1", …
$ `最高気温(℃)...8` <dbl> NA, NA, 13.3, 12.5, 13.8, 14.1, 9.7, 8.3, 8.8,…
$ `最高気温(℃)...9` <chr> NA, "品質情報", "8", "8", "8", "8", "8", "8", …
$ `最高気温(℃)...10` <chr> NA, "均質番号", "1", "1", "1", "1", "1", "1", …
$ `降水量の合計(mm)...11` <dbl> NA, NA, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 9.5…
$ `降水量の合計(mm)...12` <chr> NA, "現象なし情報", "1", "1", "1", "1", "1", "…
$ `降水量の合計(mm)...13` <chr> NA, "品質情報", "8", "8", "8", "8", "8", "8", …
$ `降水量の合計(mm)...14` <chr> NA, "均質番号", "1", "1", "1", "1", "1", "1", …
$ `日照時間(時間)...15` <dbl> NA, NA, 9.5, 4.9, 9.3, 9.2, 8.9, 8.1, 9.3, 0.3…
$ `日照時間(時間)...16` <chr> NA, "現象なし情報", "0", "0", "0", "0", "0", "…
$ `日照時間(時間)...17` <chr> NA, "品質情報", "8", "8", "8", "8", "8", "8", …
$ `日照時間(時間)...18` <chr> NA, "均質番号", "1", "1", "1", "1", "1", "1", …
$ `平均風速(m/s)...19` <dbl> NA, NA, 1.4, 1.3, 2.0, 2.3, 1.8, 1.3, 1.1, 2.2…
$ `平均風速(m/s)...20` <chr> NA, "品質情報", "8", "8", "8", "8", "8", "8", …
$ `平均風速(m/s)...21` <chr> NA, "均質番号", "1", "1", "1", "1", "1", "1", …
$ `平均雲量(10分比)...22` <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ `平均雲量(10分比)...23` <chr> NA, "品質情報", "0", "0", "0", "0", "0", "0", …
$ `平均雲量(10分比)...24` <chr> NA, "均質番号", "1", "1", "1", "1", "1", "1", …