前章までに扱ってきたtidyverseに含まれる個々のパッケージは、組み合わせて使うことでより多様な場面で活用することが期待される。例えばデータの読み込みをreadr で行い、パイプ処理でdplyr による処理を適用できる。また、データフレームに含まれる文字列変数の操作にstringr を導入することも可能である。また、tidyrverseに含まれないパッケージであってもdplyr のデータ操作関数に適用しても良い。この章では、そのようなtidyverseのパッケージの組み合わせた活用方法を見ていくことにする。新たに用いる関数については都度解説を加えていくが、個別の関数の説明は該当するパッケージを扱っている章を参照してほしい。
SNSデータの処理
それではtidyverse パッケージを読み込もう。library(tidyverse)を実行すると1章で述べたように、tidyverseに含まれる複数のパッケージが一度に利用可能な状態となる。
── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──
✔ ggplot2 3.3.5 ✔ purrr 0.3.4
✔ tibble 3.1.6 ✔ dplyr 1.0.9
✔ tidyr 1.2.0 ✔ stringr 1.4.0
✔ readr 2.1.2 ✔ forcats 0.5.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
また、追加で次のパッケージを読み込んでおく。これらは4章で扱った、文字列および日付・時間の処理を効率的に行うための関数を提供する。
# tidyverseパッケージに含まれないパッケージを追加で利用可能にしておく library (stringi)library (lubridate)
Attaching package: 'lubridate'
The following objects are masked from 'package:base':
date, intersect, setdiff, union
対象データとして、架空SNSのデータを利用する。こちらもreadr の関数を用いて作業スペースに保存しておこう。readr パッケージはtidyverseに含まれるパッケージであるため、すでにデータ読み込み関数read_csv()を呼び出せるようになっている。
# library(readr) を実行する必要はない <- read_csv ("data/sns.csv" )
Rows: 1000 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): post_id, address, place_name, user_id, nationality
dttm (1): post_time
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# データの先頭行および各変数のデータ型を確認
# A tibble: 1,000 × 6
post_id post_time address place_name user_id nationality
<chr> <dttm> <chr> <chr> <chr> <chr>
1 EM7O3RINyaLS 2016-04-01 09:37:43 石川県鳳珠郡… <NA> A-8vIm… US
2 vrpVbF83Kqhi 2016-04-01 20:54:12 大阪府大阪市… Gudetama … A-zpNo… TH
3 vwPvcEXCOa67 2016-04-01 22:01:57 大阪府泉南郡… 南海電鐵 … C-hbtH… HK
4 KPkonKKzmTep 2016-04-01 22:13:21 福島県福島市… <NA> B-QUU8… ID
5 rwaUYGGTYoqz 2016-04-02 08:18:09 千葉県成田市… Tokyo,… B-JzaP… US
6 ymuZbb5Mds54 2016-04-02 11:16:27 東京都江東区… Totem-Cir… A-G6sG… AU
7 yeQWTgSsvPYJ 2016-04-02 20:06:11 長崎県佐世保… Huis Ten … C-Nxoo… SG
8 beG3YjOzN4ac 2016-04-02 22:47:24 熊本県上益城… <NA> C-xeQ4… CN
9 ZZzCIGx6H5j7 2016-04-03 00:26:41 福岡県福岡市… <NA> B-FkHj… HK
10 GNam2fNqbeiE 2016-04-03 01:36:18 東京都江戸川… <NA> C-Bd0D… TH
# … with 990 more rows
期間を指定したデータの抽出
df_sns の変数post_timeは日付・時間を示すPOSIXctクラスである。例えばこのような変数をもつデータに対して、特定の期間だけを抽出するというような処理を実行してみよう。これを行うには2つの方法が考えられ、一つはlubridate パッケージの演算子%within%とinterval()を用いる方法、もう一つはdplyr::between()の上限と下限を設定する方法である。
# POSIXctの変数から2つの時期を指定して抽出する # %within% 演算子は lubridateパッケージに含まれる <- %>% filter (%within% interval (ymd_hms ("2016-06-01 00:00:00" ), ymd_hms ("2016-06-05 23:59:59" ))<- %>% filter (between (ymd_hms ("2016-06-01 00:00:00" ),ymd_hms ("2016-06-05 23:59:59" )# 2つの処理の結果は等しい all.equal (df_filter_date1, df_filter_date2)
なおこの例では対象の期間を指定するためにlubridate::ymd_hms()を用いたが、Rの標準関数であるSys.time()やas.POSIXct()を使って作成したPOSIXctクラスのオブジェクトであっても問題はない。
# ymd_hms()の代わりにas.POSIXct()を用いる方法 %>% filter (between (as.POSIXct (1464739200 , origin = "1970-01-01" ),as.POSIXct (1465171199 , origin = "1970-01-01" )
日付による集計
SNSデータには、投稿時間とともにユーザを識別するuser_id列がある。これを利用することで、興味のある月ごとにどれだけの投稿があったのか、どれだけのユーザが活動していたのかということや、ユーザの利用状況について集計することができる。こうした処理について、dplyr による実行例を見てみよう。
利用期間の算出
最初の例は、データ中でのユーザの利用期間について、ユーザ毎の最初と最後の投稿時間を得て、そこから算出するものである。この処理はいくつかの段階に分かれて行われる。順を追って説明しておこう。
まずlubridate::as_date()で日付・時間の変数を日付へと変換する。次にユーザごとの処理を適用するためにgroup_by()を実行し、ユーザごとのデータの集計値としてsummarise()で投稿の回数をn()で、最初と最後の投稿時間をfirst()およびlast()を使って求めている。
<- %>% # 日付・時間の変数を日付データに変換した列を追加 mutate (date = as_date (post_time)) %>% group_by (user_id) %>% # 投稿の回数, 投稿日時から最初と最後のデータを取得する summarise (n = n (),first_post = first (date),last_post = last (date))
# A tibble: 775 × 4
user_id n first_post last_post
<chr> <int> <date> <date>
1 A-0baeebfD 2 2016-05-12 2016-07-13
2 A-0BKhYkbN 1 2016-06-18 2016-06-18
3 A-0c8xSlst 2 2016-05-07 2016-05-14
4 A-0fASEKnR 1 2016-05-15 2016-05-15
5 A-0G36mkoc 1 2016-06-06 2016-06-06
6 A-0YECSFRb 1 2016-04-08 2016-04-08
7 A-1dtiP8Yq 2 2016-06-03 2016-06-18
8 A-1kIsN3FU 1 2016-05-27 2016-05-27
9 A-1MbeVyol 1 2016-06-15 2016-06-15
10 A-1Po7EMHT 1 2016-06-25 2016-06-25
# … with 765 more rows
この出力は、ユーザID user_id、投稿回数 n、投稿を行った最初と最後の日付 first_postおよびlast_postである。続いて、各ユーザの最初の投稿日と最後の投稿日からlubridate::interval()を使ってデータ中の利用期間を求める。ここで投稿が一度しかないユーザは、利用期間が0となる。また、interval()によって算出されるIntervalオブジェクトの結果を理解しやすくするため、期間を日数に変換した列を作成する。
<- %>% transmute (user_id,usage_period = interval (first_post, last_post),usage_period_days = as.numeric (usage_period, "days" ))
# A tibble: 775 × 4
user_id n usage_period usage_period_days
<chr> <int> <Interval> <dbl>
1 A-0baeebfD 2 2016-05-12 UTC--2016-07-13 UTC 62
2 A-0BKhYkbN 1 2016-06-18 UTC--2016-06-18 UTC 0
3 A-0c8xSlst 2 2016-05-07 UTC--2016-05-14 UTC 7
4 A-0fASEKnR 1 2016-05-15 UTC--2016-05-15 UTC 0
5 A-0G36mkoc 1 2016-06-06 UTC--2016-06-06 UTC 0
6 A-0YECSFRb 1 2016-04-08 UTC--2016-04-08 UTC 0
7 A-1dtiP8Yq 2 2016-06-03 UTC--2016-06-18 UTC 15
8 A-1kIsN3FU 1 2016-05-27 UTC--2016-05-27 UTC 0
9 A-1MbeVyol 1 2016-06-15 UTC--2016-06-15 UTC 0
10 A-1Po7EMHT 1 2016-06-25 UTC--2016-06-25 UTC 0
# … with 765 more rows
期間中のカウント
次は、任意の期間を設定し、期間中の投稿件数と活動のあったユーザの数を調べてみよう。ここでは月単位でのデータを扱うことにする。df_sns には月を示す変数がないため、まずは既存の変数を元に、投稿の年月を示すpost_ym列を用意する。
<- %>% transmute (# 日付・時間の変数 post_timeの値から年、月を抽出 post_ym = str_c (year (post_time), # 月の桁数を2桁に揃えるためにstringr::str_pad()を利用 str_pad (month (post_time), width = 2 , pad = "0" )))
ここでは、ユーザを識別するための user_id列以外の列は不要となるため、transmutate()を利用した。年および月の値の抽出にはlubridate の関数を使っている。また月の値が1,12と桁数が異なるため、stringr::str_pad()による桁揃えを実行した。これにより作成されたdf_sns_yr は次のようになっている。
# A tibble: 1,000 × 2
user_id post_ym
<chr> <chr>
1 A-8vImElYu 201604
2 A-zpNoCiF2 201604
3 C-hbtHidIz 201604
4 B-QUU841zl 201604
5 B-JzaPVHpY 201604
6 A-G6sGnoFV 201604
7 C-NxooWvcI 201604
8 C-xeQ41RtH 201604
9 B-FkHjECs0 201604
10 C-Bd0DCcdp 201604
# … with 990 more rows
では月ごとに全ユーザでどれだけの投稿があったかを求めよう。対象の行数を指定してカウントを行うcount()を実行するだけで計算が行われる。
# 月ごとの投稿件数 n を求める <- %>% count (post_ym)
# A tibble: 4 × 2
post_ym n
<chr> <int>
1 201604 146
2 201605 379
3 201606 325
4 201607 150
今度は、月ごとに投稿のあったユーザの数、いわゆるユニークユーザ数を調べてみよう。ユニークユーザを求めるには、1月の中で複数のデータがあるユーザに対して1つのデータとして処理する必要がある。これは次のようにdistinct()を使うことで対応できる。後の処理は上記の月ごとの投稿件数と同じであるが、最後にrename()による列名の変換を行う。
<- %>% # ユニークなデータとする組み合わせを指定 distinct (user_id, post_ym) %>% count (post_ym) %>% rename (unique_user = n)
では、月ごとのユニークユーザ数および投稿件数をまとめて見てみよう。共通のキーとなる変数をもった2つのデータを結合するleft_join()を利用する。引数by で指定するキー変数はここでは投稿月 post_ymである。先ほどユニークユーザ数の算出でカウントした変数名の変更を行ったのは、キー変数に追加しない含めないためである。
# 2つのデータフレームを結合 <- left_join (by = "post_ym"
# A tibble: 4 × 3
post_ym unique_user n
<chr> <int> <int>
1 201604 130 146
2 201605 304 379
3 201606 267 325
4 201607 130 150
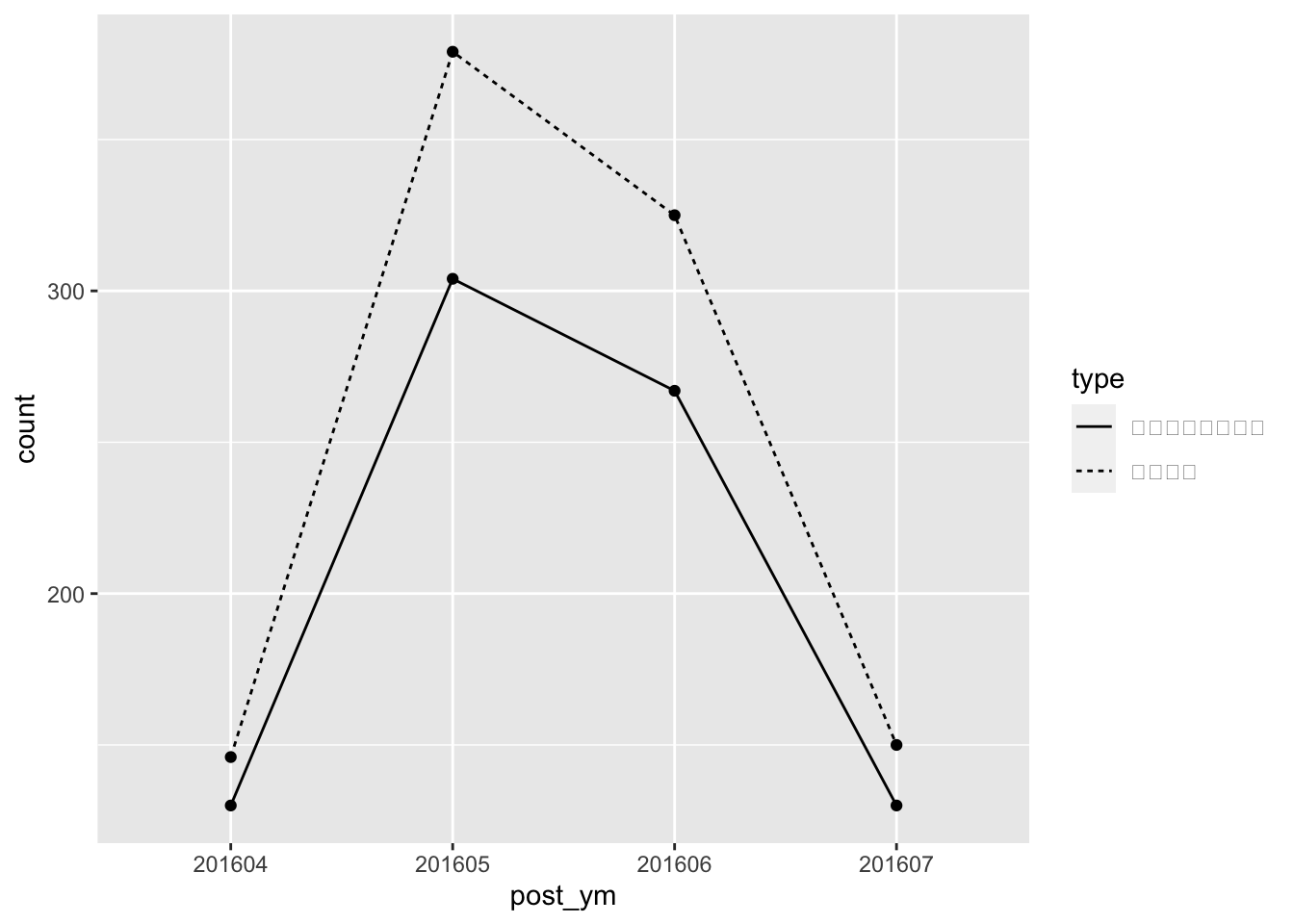
最後に、この結果を可視化するためのコードを以下に示す。ユニークユーザ数も投稿件数も、同一の月ごとに計算されたカウントの値であるため、tidyr::gather()を使い、一つの列に記録することとした。また可視化の際のラベルに日本語を用いるためにrecode()による値の置換を追加している。
<- %>% gather ("type" , "count" , - post_ym) %>% mutate (type = recode (type,n = "投稿件数" , unique_user = "ユニークユーザ数" ))
# A tibble: 8 × 3
post_ym type count
<chr> <chr> <int>
1 201604 ユニークユーザ数 130
2 201605 ユニークユーザ数 304
3 201606 ユニークユーザ数 267
4 201607 ユニークユーザ数 130
5 201604 投稿件数 146
6 201605 投稿件数 379
7 201606 投稿件数 325
8 201607 投稿件数 150
ggplot (df_sns_user_count_plot,aes (post_ym, count, group = type)) + geom_point () + geom_line (aes (lty = type))
続いて、国籍・曜日別の投稿件数を調べるという処理を示す。曜日の情報は次のようにlubridate::wday()を使うことで、日付の要素を含んだデータから簡単に求めることができる。
<- %>% # 国籍の情報がない行を除外 filter (! is.na (nationality)) %>% transmute (nationality,# 投稿時間から曜日を取得。日本語での表記を採用するため # locale引数を調整する wod = wday (post_time, label = TRUE , abbr = TRUE , locale = "ja_JP.UTF-8" ))
# A tibble: 979 × 2
nationality wod
<chr> <ord>
1 US 金
2 TH 金
3 HK 金
4 ID 金
5 US 土
6 AU 土
7 SG 土
8 CN 土
9 HK 日
10 TH 日
# … with 969 more rows
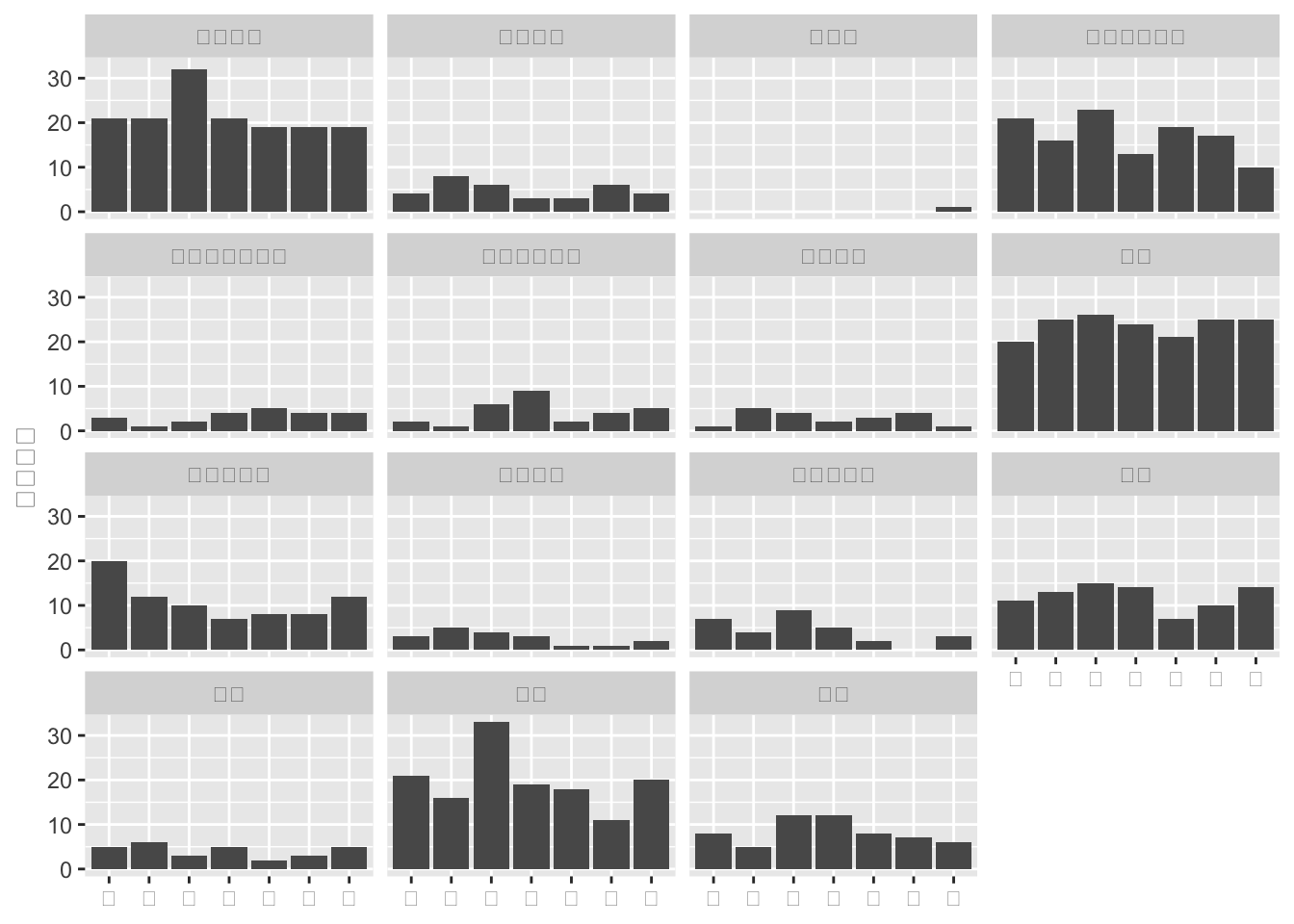
次にwday(locale = "ja_JP.UTF-8")の指定により曜日の表記が日本語になったことに対応させて、国籍名も日本語に修正し、国籍・曜日別のデータの可視化を行おう。
<- %>% mutate (nationality = recode (nationality,AU = "オーストラリア" ,CN = "中国" ,ES = "スペイン" ,FR = "フランス" ,GB = "イギリス" ,HK = "香港" ,ID = "インドネシア" ,IN = "インド" ,KR = "韓国" ,MY = "マレーシア" ,PH = "フィリピン" ,SG = "シンガポール" ,TH = "タイ" ,TW = "台湾" ,US = "アメリカ" ))
%>% count (wod, nationality) %>% ggplot (aes (wod, n)) + geom_bar (stat = "identity" ) + xlab (NULL ) + ylab ("投稿件数" ) + facet_wrap (~ nationality)
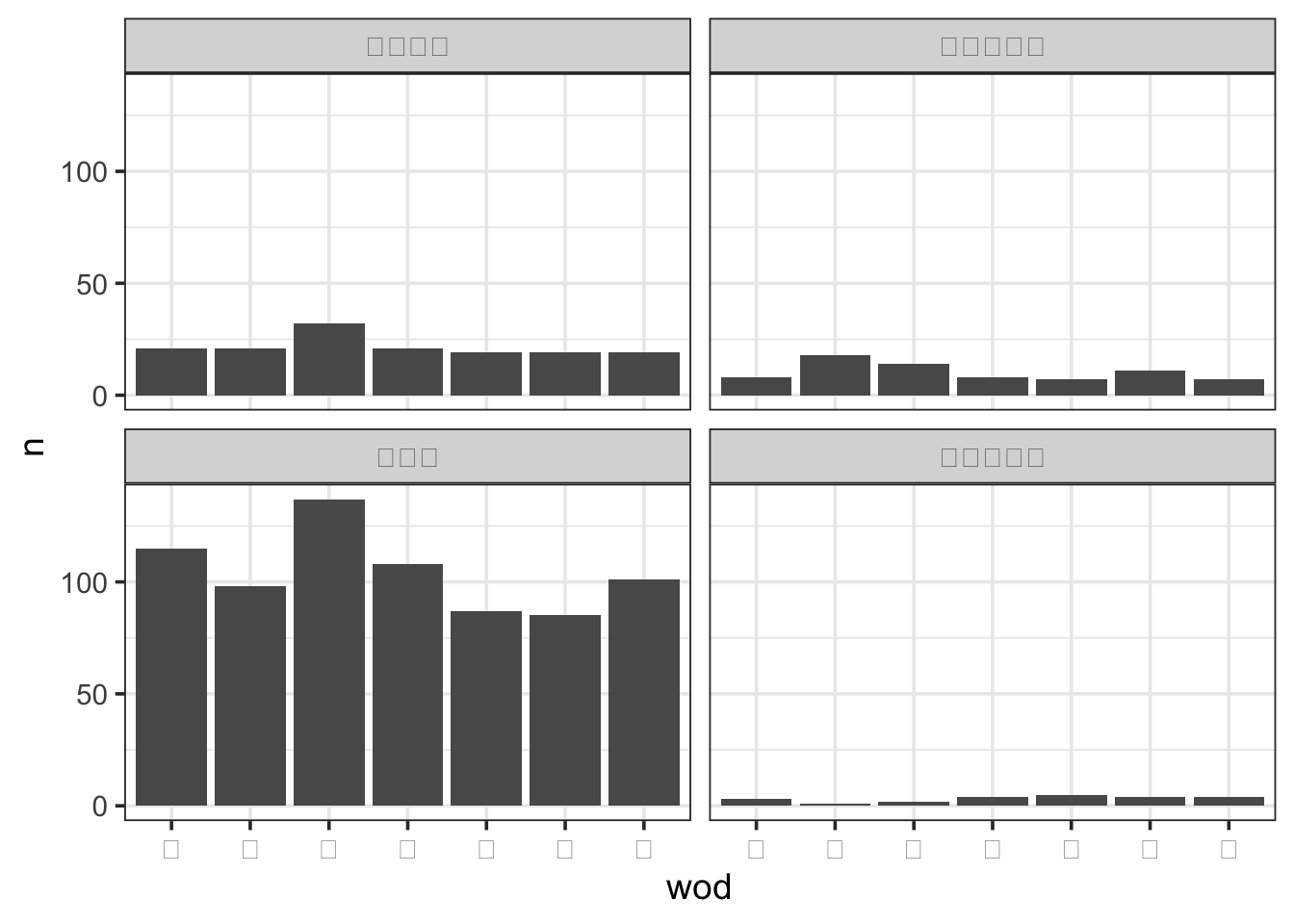
同様に、国籍を大陸ごとにまとめてプロットを行う例を以下に示す。
%>% mutate (continent = fct_collapse (nationality,= c ("中国" , "香港" , "インドネシア" , "インド" , "韓国" , "マレーシア" , "フィリピン" , "シンガポール" , "タイ" , "台湾" ),= c ("アメリカ" ),= c ("スペイン" , "フランス" , "イギリス" ),= c ("オーストラリア" ))) %>% count (wod, continent) %>% ggplot (aes (wod, n)) + geom_bar (stat = "identity" ) + facet_wrap (~ continent) + theme_bw (base_size = 14 )
地名の分割
df_sns に記録されているaddress列は、都道府県名、市区町村名、町字の3要素に分解可能な住所文字列である。これをdplyr を使い、データフレームを対象とした操作で個々の要素に分割した列を作成する処理を考えてみよう。
# addressには住所が記録されている $ address[1 : 5 ]
[1] "石川県鳳珠郡 能登町" "大阪府大阪市 北区角田町5"
[3] "大阪府泉南郡 田尻町泉州空港中1" "福島県福島市入江町1"
[5] "千葉県成田市木の根3"
ここではstringr パッケージの関数を用いる例を説明する。都道府県と市区町村の抽出にはそれぞれ、文字列置換の関数str_replace()と文字列分割の関数str_split()を使う。データフレームに対して処理を適用する前にまずはベクトルを操作対象として結果を確認しておこう。
都道府県名を取得するために、「都」、「道」、「府」、「県」を境界とし、前半を都道府県名にするパターンが考えられる。一方でこのパターンでは「京都府」の分割に失敗してしまう。そこで「都」の代わりに「東京都」を指定した次のパターンを実行することにする。
# 抽出に失敗するパターン str_replace (c ("東京都渋谷区桜ヶ丘" , "岡山県岡山市北区清心町" , "茨城県つくば市小野川" ,"京都府舞鶴市字浜" ), pattern = "(都|道|府|県).+" , replacement = " \\ 1" )
[1] "東京都" "岡山県" "茨城県" "京都"
# 都道府県名の抽出 # 一致したパターンを再利用するために後方参照を行う str_replace (df_sns$ address[5 : 10 ], pattern = "(東京都|道|府|県).+" , replacement = " \\ 1" )
[1] "千葉県" "東京都" "長崎県" "熊本県" "福岡県" "東京都"
次に市区町村名であるが、これは先ほどの都道府県以降の文字列を得るために分割を行い、その後改めて後方参照による文字列置換を行うという方法をとる。
# 市区町村名の抽出 str_split (df_sns$ address[15 : 20 ], pattern = "(東京都|道|府|県)" , n = 2 ) %>% :: map_chr (2 ) %>% str_replace (string = ., pattern = "(区|市|.+市 .+区|町|村).+" , replacement = " \\ 1" )
[1] "成田市" "泉南郡 田尻町" "渋谷区" "新宿区"
[5] "御殿場市" "松戸市"
ベクトルでの結果を確認したら、次はその処理をdplyr を使いデータフレームへ適用しよう。変数の参照にデータフレームのオブジェクト名とドル記号を省略し、変数名を直接指定したものを、transmute()あるいはmutate()へとコピーペーストするだけで良い。
# transmute内の変数への処理は上記のコードをコピーペーストしたもの %>% transmute (address,geo_prefecture = str_replace (address, "(東京都|道|府|県).+" , " \\ 1" ),geo_city = str_split (address, "(東京都|道|府|県)" , n = 2 ) %>% map_chr (2 ) %>% str_replace (string = ., pattern = "(区|市|.+市 .+区|町|村).+" , replacement = " \\ 1" ))
# A tibble: 1,000 × 3
address geo_prefecture geo_city
<chr> <chr> <chr>
1 石川県鳳珠郡 能登町 石川県 鳳珠郡 能登町
2 大阪府大阪市 北区角田町5 大阪府 大阪市 北区
3 大阪府泉南郡 田尻町泉州空港中1 大阪府 泉南郡 田尻町
4 福島県福島市入江町1 福島県 福島市
5 千葉県成田市木の根3 千葉県 成田市
6 東京都江東区青海一丁目1 東京都 江東区
7 長崎県佐世保市ハウステンボス町8 長崎県 佐世保市
8 熊本県上益城郡 嘉島町 熊本県 上益城郡 嘉島町
9 福岡県福岡市 中央区 福岡県 福岡市
10 東京都江戸川区東葛西五丁目19 東京都 江戸川区
# … with 990 more rows
入れ子データへのグループ処理
グループ化したデータに含まれる値を操作するには、データを入れ子にしておくと便利である。ここではtidyr とpurrr による入れ子データへのグループ処理の例を見ていこう。
まず処理を別々に適用したい入れ子データの作成であるが、これはtidyr::nest()を直接使う方法とdplyr::group_by()を間にはさむ実行方法がある。次の例はdf_sns データの国籍 nationality列ごとにデータをグループ化し、入れ子データとして格納するものであるが、いずれも結果は等しい。
<- %>% group_by (nationality) %>% nest ()# 上記のコードと同じ処理を実行 <- %>% nest (- nationality)
Warning: All elements of `...` must be named.
Did you want `data = -nationality`?
では国籍ごとに投稿件数が多いユーザ上位3名のuser_idおよび投稿件数を抽出する処理を実行しよう。ここで入れ子データへの関数の適用はpurrr のmap*()を使う。
%>% transmute (max_n = map (data, ~ %>% count (user_id) %>% top_n (3 , wt = n))%>% unnest ()
Warning: `cols` is now required when using unnest().
Please use `cols = c(max_n)`
# A tibble: 165 × 3
nationality user_id n
<chr> <chr> <int>
1 US A-Tz38wKFN 3
2 US C-EWrFgfFO 3
3 US C-vXf2Pfso 3
4 TH A-hmIIeiyU 3
5 TH B-3rIzdYs2 10
6 TH C-v48Px9pW 4
7 TH C-VaZADtzv 3
8 HK C-3njvd4vb 9
9 HK C-hbtHidIz 5
10 HK C-OvYgclto 5
# … with 155 more rows
もう一つ、今度は国籍別の投稿件数とユニークユーザ数を求める処理を示す。
%>% transmute (n = map_int (data, ~ nrow (..1 )),uu = map_int (data, ~ ..1 %>% distinct (user_id) %>% nrow ())
# A tibble: 16 × 3
nationality n uu
<chr> <int> <int>
1 US 152 134
2 TH 166 131
3 HK 58 35
4 ID 119 97
5 AU 23 23
6 SG 29 29
7 CN 84 62
8 MY 30 26
9 PH 77 67
10 KR 138 67
11 GB 34 32
12 ES 20 16
13 FR 19 14
14 <NA> 21 21
15 TW 29 24
16 IN 1 1